The good news is that there are a number of techniques that may be applied to inherently sequential designs. The bad news is that there are a number of techniques that may be applied to inherently sequential designs — and none of them are guaranteed to work in all cases, at least given the ever-present constraints on time, effort, and cost.
Here are a few such techniques:
Most of all, be patient and plan ahead. If your program contains decades of sequential assumptions in its design, APIs, and code, you probably aren't going to be able to fix them all in a single weekend, no matter how much coffee (or, in Europe, beer) you drink. Measure the performance and scalability, locate the bottlenecks, and fix the worst first. Always keep in mind the possibility of redesigning based on existing scalable code. For example, perhaps you can replace much of your application with a database, perhaps you can use a parallel sort library, perhaps you can simply run multiple single-threaded instances of your application, and so on.
But this still leaves an important question unanswered: are existing single-threaded designs, APIs, and code really a problem?
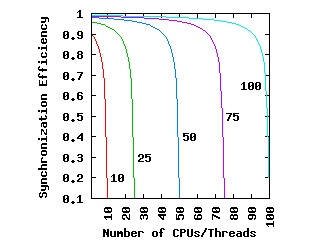
The answer is, as always, “it depends.” What it depends on is how much work is done per global shared-memory update and how many CPUs are concurrently running in the application. The following plot shows data from a crude queueing-model analysis of the situtation:
Synchronization efficiency (the y axis) is the ratio of the time required for the work at hand to the time required for both the work and the synchronization. If your application is to scale well, its synchronization efficiency must be close to 1.0. Putting it another way, if your application's synchronization efficiency is 0.1 (or, if you prefer, 10%), then your application is wasting 90% of the CPU time it is using, requiring no fewer than ten CPUs to achieve the same throughput that a single CPU would achieve given a single-threaded version of your application.
Each trace corresponds to a unit of work whose average overhead is the specified multiple of that of synchronization overhead. So, if a unit of work takes about ten times as long as an atomic increment, synchronization efficiency drops off dramatically as the number of CPUs approaches ten.
Looking at the trace labeled “100”, we see that if the application is to scale to anywhere near 100 CPUs, each unit of work must consume more than 100 times more time than a single synchronization operation. On modern CPUs, this means that each unit of work must entail many thousands of instructions.
In short, if you were thinking of scaling your application by handing a single “add” instruction out to each thread while using an atomic increment of a global variable for synchronization, you really need to think again. You will instead need about 100,000 “add” instructions per unit of work to scale to 100 CPUs. If you want to scale to more than 100 CPUs, you will need more than 100,000 “add” instructions.
Alternatively, you will need to use something considerably more scalable for your synchronization than that atomic increment of a global variable, for example, using one of the techniques listed above.