This section covers the functions used to allocate, initialise, copy and destroy memory descriptors.
The initial mm_struct in the system is called init_mm and is statically initialised at compile time using the macro INIT_MM().
238 #define INIT_MM(name) \
239 { \
240 mm_rb: RB_ROOT, \
241 pgd: swapper_pg_dir, \
242 mm_users: ATOMIC_INIT(2), \
243 mm_count: ATOMIC_INIT(1), \
244 mmap_sem: __RWSEM_INITIALIZER(name.mmap_sem),\
245 page_table_lock: SPIN_LOCK_UNLOCKED, \
246 mmlist: LIST_HEAD_INIT(name.mmlist), \
247 }
Once it is established, new mm_structs are copies of their parent mm_struct and are copied using copy_mm() with the process specific fields initialised with init_mm().
This function makes a copy of the mm_struct for the given task. This is only called from do_fork() after a new process has been created and needs its own mm_struct.
315 static int copy_mm(unsigned long clone_flags,
struct task_struct * tsk)
316 {
317 struct mm_struct * mm, *oldmm;
318 int retval;
319
320 tsk->min_flt = tsk->maj_flt = 0;
321 tsk->cmin_flt = tsk->cmaj_flt = 0;
322 tsk->nswap = tsk->cnswap = 0;
323
324 tsk->mm = NULL;
325 tsk->active_mm = NULL;
326
327 /*
328 * Are we cloning a kernel thread?
330 * We need to steal a active VM for that..
331 */
332 oldmm = current->mm;
333 if (!oldmm)
334 return 0;
335
336 if (clone_flags & CLONE_VM) {
337 atomic_inc(&oldmm->mm_users);
338 mm = oldmm;
339 goto good_mm;
340 }
Reset fields that are not inherited by a child mm_struct and find a mm to copy from.
342 retval = -ENOMEM; 343 mm = allocate_mm(); 344 if (!mm) 345 goto fail_nomem; 346 347 /* Copy the current MM stuff.. */ 348 memcpy(mm, oldmm, sizeof(*mm)); 349 if (!mm_init(mm)) 350 goto fail_nomem; 351 352 if (init_new_context(tsk,mm)) 353 goto free_pt; 354 355 down_write(&oldmm->mmap_sem); 356 retval = dup_mmap(mm); 357 up_write(&oldmm->mmap_sem); 358
359 if (retval) 360 goto free_pt; 361 362 /* 363 * child gets a private LDT (if there was an LDT in the parent) 364 */ 365 copy_segments(tsk, mm); 366 367 good_mm: 368 tsk->mm = mm; 369 tsk->active_mm = mm; 370 return 0; 371 372 free_pt: 373 mmput(mm); 374 fail_nomem: 375 return retval; 376 }
This function initialises process specific mm fields.
230 static struct mm_struct * mm_init(struct mm_struct * mm)
231 {
232 atomic_set(&mm->mm_users, 1);
233 atomic_set(&mm->mm_count, 1);
234 init_rwsem(&mm->mmap_sem);
235 mm->page_table_lock = SPIN_LOCK_UNLOCKED;
236 mm->pgd = pgd_alloc(mm);
237 mm->def_flags = 0;
238 if (mm->pgd)
239 return mm;
240 free_mm(mm);
241 return NULL;
242 }
Two functions are provided allocating a mm_struct. To be slightly confusing, they are essentially the name. allocate_mm() will allocate a mm_struct from the slab allocator. mm_alloc() will allocate the struct and then call the function mm_init() to initialise it.
227 #define allocate_mm() (kmem_cache_alloc(mm_cachep, SLAB_KERNEL))
248 struct mm_struct * mm_alloc(void)
249 {
250 struct mm_struct * mm;
251
252 mm = allocate_mm();
253 if (mm) {
254 memset(mm, 0, sizeof(*mm));
255 return mm_init(mm);
256 }
257 return NULL;
258 }
A new user to an mm increments the usage count with a simple call,
atomic_inc(&mm->mm_users};
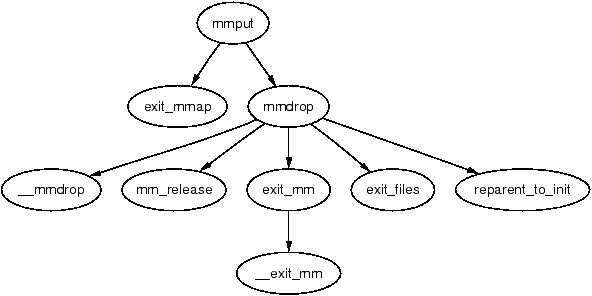
It is decremented with a call to mmput(). If the mm_users count reaches zero, all the mapped regions are deleted with exit_mmap() and the page tables destroyed as there is no longer any users of the userspace portions. The mm_count count is decremented with mmdrop() as all the users of the page tables and VMAs are counted as one mm_struct user. When mm_count reaches zero, the mm_struct will be destroyed.
Figure D.1: Call Graph: mmput()
276 void mmput(struct mm_struct *mm)
277 {
278 if (atomic_dec_and_lock(&mm->mm_users, &mmlist_lock)) {
279 extern struct mm_struct *swap_mm;
280 if (swap_mm == mm)
281 swap_mm = list_entry(mm->mmlist.next,
struct mm_struct, mmlist);
282 list_del(&mm->mmlist);
283 mmlist_nr--;
284 spin_unlock(&mmlist_lock);
285 exit_mmap(mm);
286 mmdrop(mm);
287 }
288 }
765 static inline void mmdrop(struct mm_struct * mm)
766 {
767 if (atomic_dec_and_test(&mm->mm_count))
768 __mmdrop(mm);
769 }
265 inline void __mmdrop(struct mm_struct *mm)
266 {
267 BUG_ON(mm == &init_mm);
268 pgd_free(mm->pgd);
269 destroy_context(mm);
270 free_mm(mm);
271 }
This large section deals with the creation, deletion and manipulation of memory regions.
The main call graph for creating a memory region is shown in Figure 4.4.
This is a very simply wrapper function around do_mmap_pgoff() which performs most of the work.
557 static inline unsigned long do_mmap(struct file *file,
unsigned long addr,
558 unsigned long len, unsigned long prot,
559 unsigned long flag, unsigned long offset)
560 {
561 unsigned long ret = -EINVAL;
562 if ((offset + PAGE_ALIGN(len)) < offset)
563 goto out;
564 if (!(offset & ~PAGE_MASK))
565 ret = do_mmap_pgoff(file, addr, len, prot, flag,
offset >> PAGE_SHIFT);
566 out:
567 return ret;
568 }
This function is very large and so is broken up into a number of sections. Broadly speaking the sections are
393 unsigned long do_mmap_pgoff(struct file * file,
unsigned long addr,
unsigned long len, unsigned long prot,
394 unsigned long flags, unsigned long pgoff)
395 {
396 struct mm_struct * mm = current->mm;
397 struct vm_area_struct * vma, * prev;
398 unsigned int vm_flags;
399 int correct_wcount = 0;
400 int error;
401 rb_node_t ** rb_link, * rb_parent;
402
403 if (file && (!file->f_op || !file->f_op->mmap))
404 return -ENODEV;
405
406 if (!len)
407 return addr;
408
409 len = PAGE_ALIGN(len);
410
if (len > TASK_SIZE || len == 0)
return -EINVAL;
413
414 /* offset overflow? */
415 if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
416 return -EINVAL;
417
418 /* Too many mappings? */
419 if (mm->map_count > max_map_count)
420 return -ENOMEM;
421
422 /* Obtain the address to map to. we verify (or select) it and 423 * ensure that it represents a valid section of the address space. 424 */ 425 addr = get_unmapped_area(file, addr, len, pgoff, flags); 426 if (addr & ~PAGE_MASK) 427 return addr; 428
429 /* Do simple checking here so the lower-level routines won't have
430 * to. we assume access permissions have been handled by the open
431 * of the memory object, so we don't do any here.
432 */
433 vm_flags = calc_vm_flags(prot,flags) | mm->def_flags
| VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
434
435 /* mlock MCL_FUTURE? */
436 if (vm_flags & VM_LOCKED) {
437 unsigned long locked = mm->locked_vm << PAGE_SHIFT;
438 locked += len;
439 if (locked > current->rlim[RLIMIT_MEMLOCK].rlim_cur)
440 return -EAGAIN;
441 }
442
443 if (file) {
444 switch (flags & MAP_TYPE) {
445 case MAP_SHARED:
446 if ((prot & PROT_WRITE) &&
!(file->f_mode & FMODE_WRITE))
447 return -EACCES;
448
449 /* Make sure we don't allow writing to
an append-only file.. */
450 if (IS_APPEND(file->f_dentry->d_inode) &&
(file->f_mode & FMODE_WRITE))
451 return -EACCES;
452
453 /* make sure there are no mandatory
locks on the file. */
454 if (locks_verify_locked(file->f_dentry->d_inode))
455 return -EAGAIN;
456
457 vm_flags |= VM_SHARED | VM_MAYSHARE;
458 if (!(file->f_mode & FMODE_WRITE))
459 vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
460
461 /* fall through */
462 case MAP_PRIVATE:
463 if (!(file->f_mode & FMODE_READ))
464 return -EACCES;
465 break;
466
467 default:
468 return -EINVAL;
469 }
470 } else {
471 vm_flags |= VM_SHARED | VM_MAYSHARE;
472 switch (flags & MAP_TYPE) {
473 default:
474 return -EINVAL;
475 case MAP_PRIVATE:
476 vm_flags &= ~(VM_SHARED | VM_MAYSHARE);
477 /* fall through */
478 case MAP_SHARED:
479 break;
480 }
481 }
483 /* Clear old maps */
484 munmap_back:
485 vma = find_vma_prepare(mm, addr, &prev, &rb_link, &rb_parent);
486 if (vma && vma->vm_start < addr + len) {
487 if (do_munmap(mm, addr, len))
488 return -ENOMEM;
489 goto munmap_back;
490 }
491
492 /* Check against address space limit. */
493 if ((mm->total_vm << PAGE_SHIFT) + len
494 > current->rlim[RLIMIT_AS].rlim_cur)
495 return -ENOMEM;
496
497 /* Private writable mapping? Check memory availability.. */
498 if ((vm_flags & (VM_SHARED | VM_WRITE)) == VM_WRITE &&
499 !(flags & MAP_NORESERVE) &&
500 !vm_enough_memory(len >> PAGE_SHIFT))
501 return -ENOMEM;
502
503 /* Can we just expand an old anonymous mapping? */
504 if (!file && !(vm_flags & VM_SHARED) && rb_parent)
505 if (vma_merge(mm, prev, rb_parent,
addr, addr + len, vm_flags))
506 goto out;
507
508 /* Determine the object being mapped and call the appropriate 509 * specific mapper. the address has already been validated, but 510 * not unmapped, but the maps are removed from the list. 511 */ 512 vma = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL); 513 if (!vma) 514 return -ENOMEM; 515 516 vma->vm_mm = mm; 517 vma->vm_start = addr; 518 vma->vm_end = addr + len; 519 vma->vm_flags = vm_flags; 520 vma->vm_page_prot = protection_map[vm_flags & 0x0f]; 521 vma->vm_ops = NULL; 522 vma->vm_pgoff = pgoff; 523 vma->vm_file = NULL; 524 vma->vm_private_data = NULL; 525 vma->vm_raend = 0;
527 if (file) {
528 error = -EINVAL;
529 if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
530 goto free_vma;
531 if (vm_flags & VM_DENYWRITE) {
532 error = deny_write_access(file);
533 if (error)
534 goto free_vma;
535 correct_wcount = 1;
536 }
537 vma->vm_file = file;
538 get_file(file);
539 error = file->f_op->mmap(file, vma);
540 if (error)
541 goto unmap_and_free_vma;
542 } else if (flags & MAP_SHARED) {
543 error = shmem_zero_setup(vma);
544 if (error)
545 goto free_vma;
546 }
547
548 /* Can addr have changed??
549 *
550 * Answer: Yes, several device drivers can do it in their
551 * f_op->mmap method. -DaveM
552 */
553 if (addr != vma->vm_start) {
554 /*
555 * It is a bit too late to pretend changing the virtual
556 * area of the mapping, we just corrupted userspace
557 * in the do_munmap, so FIXME (not in 2.4 to avoid
558 * breaking the driver API).
559 */
560 struct vm_area_struct * stale_vma;
561 /* Since addr changed, we rely on the mmap op to prevent
562 * collisions with existing vmas and just use
563 * find_vma_prepare to update the tree pointers.
564 */
565 addr = vma->vm_start;
566 stale_vma = find_vma_prepare(mm, addr, &prev,
567 &rb_link, &rb_parent);
568 /*
569 * Make sure the lowlevel driver did its job right.
570 */
571 if (unlikely(stale_vma && stale_vma->vm_start <
vma->vm_end)) {
572 printk(KERN_ERR "buggy mmap operation: [<%p>]\n",
573 file ? file->f_op->mmap : NULL);
574 BUG();
575 }
576 }
577
578 vma_link(mm, vma, prev, rb_link, rb_parent);
579 if (correct_wcount)
580 atomic_inc(&file->f_dentry->d_inode->i_writecount);
581
582 out:
583 mm->total_vm += len >> PAGE_SHIFT;
584 if (vm_flags & VM_LOCKED) {
585 mm->locked_vm += len >> PAGE_SHIFT;
586 make_pages_present(addr, addr + len);
587 }
588 return addr;
589
590 unmap_and_free_vma:
591 if (correct_wcount)
592 atomic_inc(&file->f_dentry->d_inode->i_writecount);
593 vma->vm_file = NULL;
594 fput(file);
595
596 /* Undo any partial mapping done by a device driver. */
597 zap_page_range(mm, vma->vm_start, vma->vm_end - vma->vm_start);
598 free_vma:
599 kmem_cache_free(vm_area_cachep, vma);
600 return error;
601 }
The call graph for insert_vm_struct() is shown in Figure 4.6.
This is the top level function for inserting a new vma into an address space. There is a second function like it called simply insert_vm_struct() that is not described in detail here as the only difference is the one line of code increasing the map_count.
1174 void __insert_vm_struct(struct mm_struct * mm,
struct vm_area_struct * vma)
1175 {
1176 struct vm_area_struct * __vma, * prev;
1177 rb_node_t ** rb_link, * rb_parent;
1178
1179 __vma = find_vma_prepare(mm, vma->vm_start, &prev,
&rb_link, &rb_parent);
1180 if (__vma && __vma->vm_start < vma->vm_end)
1181 BUG();
1182 __vma_link(mm, vma, prev, rb_link, rb_parent);
1183 mm->map_count++;
1184 validate_mm(mm);
1185 }
This is responsible for finding the correct places to insert a VMA at the supplied address. It returns a number of pieces of information via the actual return and the function arguments. The forward VMA to link to is returned with return. pprev is the previous node which is required because the list is a singly linked list. rb_link and rb_parent are the parent and leaf node the new VMA will be inserted between.
246 static struct vm_area_struct * find_vma_prepare(
struct mm_struct * mm,
unsigned long addr,
247 struct vm_area_struct ** pprev,
248 rb_node_t *** rb_link,
rb_node_t ** rb_parent)
249 {
250 struct vm_area_struct * vma;
251 rb_node_t ** __rb_link, * __rb_parent, * rb_prev;
252
253 __rb_link = &mm->mm_rb.rb_node;
254 rb_prev = __rb_parent = NULL;
255 vma = NULL;
256
257 while (*__rb_link) {
258 struct vm_area_struct *vma_tmp;
259
260 __rb_parent = *__rb_link;
261 vma_tmp = rb_entry(__rb_parent,
struct vm_area_struct, vm_rb);
262
263 if (vma_tmp->vm_end > addr) {
264 vma = vma_tmp;
265 if (vma_tmp->vm_start <= addr)
266 return vma;
267 __rb_link = &__rb_parent->rb_left;
268 } else {
269 rb_prev = __rb_parent;
270 __rb_link = &__rb_parent->rb_right;
271 }
272 }
273
274 *pprev = NULL;
275 if (rb_prev)
276 *pprev = rb_entry(rb_prev, struct vm_area_struct, vm_rb);
277 *rb_link = __rb_link;
278 *rb_parent = __rb_parent;
279 return vma;
280 }
This is the top-level function for linking a VMA into the proper lists. It is responsible for acquiring the necessary locks to make a safe insertion
337 static inline void vma_link(struct mm_struct * mm,
struct vm_area_struct * vma,
struct vm_area_struct * prev,
338 rb_node_t ** rb_link, rb_node_t * rb_parent)
339 {
340 lock_vma_mappings(vma);
341 spin_lock(&mm->page_table_lock);
342 __vma_link(mm, vma, prev, rb_link, rb_parent);
343 spin_unlock(&mm->page_table_lock);
344 unlock_vma_mappings(vma);
345
346 mm->map_count++;
347 validate_mm(mm);
348 }
This simply calls three helper functions which are responsible for linking the VMA into the three linked lists that link VMAs together.
329 static void __vma_link(struct mm_struct * mm,
struct vm_area_struct * vma,
struct vm_area_struct * prev,
330 rb_node_t ** rb_link, rb_node_t * rb_parent)
331 {
332 __vma_link_list(mm, vma, prev, rb_parent);
333 __vma_link_rb(mm, vma, rb_link, rb_parent);
334 __vma_link_file(vma);
335 }
282 static inline void __vma_link_list(struct mm_struct * mm,
struct vm_area_struct * vma,
struct vm_area_struct * prev,
283 rb_node_t * rb_parent)
284 {
285 if (prev) {
286 vma->vm_next = prev->vm_next;
287 prev->vm_next = vma;
288 } else {
289 mm->mmap = vma;
290 if (rb_parent)
291 vma->vm_next = rb_entry(rb_parent,
struct vm_area_struct,
vm_rb);
292 else
293 vma->vm_next = NULL;
294 }
295 }
The principal workings of this function are stored within <linux/rbtree.h> and will not be discussed in detail in this book.
297 static inline void __vma_link_rb(struct mm_struct * mm,
struct vm_area_struct * vma,
298 rb_node_t ** rb_link,
rb_node_t * rb_parent)
299 {
300 rb_link_node(&vma->vm_rb, rb_parent, rb_link);
301 rb_insert_color(&vma->vm_rb, &mm->mm_rb);
302 }
This function links the VMA into a linked list of shared file mappings.
304 static inline void __vma_link_file(struct vm_area_struct * vma)
305 {
306 struct file * file;
307
308 file = vma->vm_file;
309 if (file) {
310 struct inode * inode = file->f_dentry->d_inode;
311 struct address_space *mapping = inode->i_mapping;
312 struct vm_area_struct **head;
313
314 if (vma->vm_flags & VM_DENYWRITE)
315 atomic_dec(&inode->i_writecount);
316
317 head = &mapping->i_mmap;
318 if (vma->vm_flags & VM_SHARED)
319 head = &mapping->i_mmap_shared;
320
321 /* insert vma into inode's share list */
322 if((vma->vm_next_share = *head) != NULL)
323 (*head)->vm_pprev_share = &vma->vm_next_share;
324 *head = vma;
325 vma->vm_pprev_share = head;
326 }
327 }
This function checks to see if a region pointed to be prev may be expanded forwards to cover the area from addr to end instead of allocating a new VMA. If it cannot, the VMA ahead is checked to see can it be expanded backwards instead.
350 static int vma_merge(struct mm_struct * mm,
struct vm_area_struct * prev,
351 rb_node_t * rb_parent,
unsigned long addr, unsigned long end,
unsigned long vm_flags)
352 {
353 spinlock_t * lock = &mm->page_table_lock;
354 if (!prev) {
355 prev = rb_entry(rb_parent, struct vm_area_struct, vm_rb);
356 goto merge_next;
357 }
358 if (prev->vm_end == addr && can_vma_merge(prev, vm_flags)) {
359 struct vm_area_struct * next;
360
361 spin_lock(lock);
362 prev->vm_end = end;
363 next = prev->vm_next;
364 if (next && prev->vm_end == next->vm_start &&
can_vma_merge(next, vm_flags)) {
365 prev->vm_end = next->vm_end;
366 __vma_unlink(mm, next, prev);
367 spin_unlock(lock);
368
369 mm->map_count--;
370 kmem_cache_free(vm_area_cachep, next);
371 return 1;
372 }
373 spin_unlock(lock);
374 return 1;
375 }
376
377 prev = prev->vm_next;
378 if (prev) {
379 merge_next:
380 if (!can_vma_merge(prev, vm_flags))
381 return 0;
382 if (end == prev->vm_start) {
383 spin_lock(lock);
384 prev->vm_start = addr;
385 spin_unlock(lock);
386 return 1;
387 }
388 }
389
390 return 0;
391 }
This trivial function checks to see if the permissions of the supplied VMA match the permissions in vm_flags
582 static inline int can_vma_merge(struct vm_area_struct * vma,
unsigned long vm_flags)
583 {
584 if (!vma->vm_file && vma->vm_flags == vm_flags)
585 return 1;
586 else
587 return 0;
588 }
The call graph for this function is shown in Figure 4.7. This is the system service call to remap a memory region
347 asmlinkage unsigned long sys_mremap(unsigned long addr,
348 unsigned long old_len, unsigned long new_len,
349 unsigned long flags, unsigned long new_addr)
350 {
351 unsigned long ret;
352
353 down_write(¤t->mm->mmap_sem);
354 ret = do_mremap(addr, old_len, new_len, flags, new_addr);
355 up_write(¤t->mm->mmap_sem);
356 return ret;
357 }
This function does most of the actual “work” required to remap, resize and move a memory region. It is quite long but can be broken up into distinct parts which will be dealt with separately here. The tasks are broadly speaking
219 unsigned long do_mremap(unsigned long addr,
220 unsigned long old_len, unsigned long new_len,
221 unsigned long flags, unsigned long new_addr)
222 {
223 struct vm_area_struct *vma;
224 unsigned long ret = -EINVAL;
225
226 if (flags & ~(MREMAP_FIXED | MREMAP_MAYMOVE))
227 goto out;
228
229 if (addr & ~PAGE_MASK)
230 goto out;
231
232 old_len = PAGE_ALIGN(old_len);
233 new_len = PAGE_ALIGN(new_len);
234
236 if (flags & MREMAP_FIXED) {
237 if (new_addr & ~PAGE_MASK)
238 goto out;
239 if (!(flags & MREMAP_MAYMOVE))
240 goto out;
241
242 if (new_len > TASK_SIZE || new_addr > TASK_SIZE - new_len)
243 goto out;
244
245 /* Check if the location we're moving into overlaps the
246 * old location at all, and fail if it does.
247 */
248 if ((new_addr <= addr) && (new_addr+new_len) > addr)
249 goto out;
250
251 if ((addr <= new_addr) && (addr+old_len) > new_addr)
252 goto out;
253
254 do_munmap(current->mm, new_addr, new_len);
255 }
This block handles the condition where the region location is fixed and must be fully moved. It ensures the area been moved to is safe and definitely unmapped.
261 ret = addr;
262 if (old_len >= new_len) {
263 do_munmap(current->mm, addr+new_len, old_len - new_len);
264 if (!(flags & MREMAP_FIXED) || (new_addr == addr))
265 goto out;
266 }
271 ret = -EFAULT;
272 vma = find_vma(current->mm, addr);
273 if (!vma || vma->vm_start > addr)
274 goto out;
275 /* We can't remap across vm area boundaries */
276 if (old_len > vma->vm_end - addr)
277 goto out;
278 if (vma->vm_flags & VM_DONTEXPAND) {
279 if (new_len > old_len)
280 goto out;
281 }
282 if (vma->vm_flags & VM_LOCKED) {
283 unsigned long locked = current->mm->locked_vm << PAGE_SHIFT;
284 locked += new_len - old_len;
285 ret = -EAGAIN;
286 if (locked > current->rlim[RLIMIT_MEMLOCK].rlim_cur)
287 goto out;
288 }
289 ret = -ENOMEM;
290 if ((current->mm->total_vm << PAGE_SHIFT) + (new_len - old_len)
291 > current->rlim[RLIMIT_AS].rlim_cur)
292 goto out;
293 /* Private writable mapping? Check memory availability.. */
294 if ((vma->vm_flags & (VM_SHARED | VM_WRITE)) == VM_WRITE &&
295 !(flags & MAP_NORESERVE) &&
296 !vm_enough_memory((new_len - old_len) >> PAGE_SHIFT))
297 goto out;
Do a number of checks to make sure it is safe to grow or move the region
302 if (old_len == vma->vm_end - addr &&
303 !((flags & MREMAP_FIXED) && (addr != new_addr)) &&
304 (old_len != new_len || !(flags & MREMAP_MAYMOVE))) {
305 unsigned long max_addr = TASK_SIZE;
306 if (vma->vm_next)
307 max_addr = vma->vm_next->vm_start;
308 /* can we just expand the current mapping? */
309 if (max_addr - addr >= new_len) {
310 int pages = (new_len - old_len) >> PAGE_SHIFT;
311 spin_lock(&vma->vm_mm->page_table_lock);
312 vma->vm_end = addr + new_len;
313 spin_unlock(&vma->vm_mm->page_table_lock);
314 current->mm->total_vm += pages;
315 if (vma->vm_flags & VM_LOCKED) {
316 current->mm->locked_vm += pages;
317 make_pages_present(addr + old_len,
318 addr + new_len);
319 }
320 ret = addr;
321 goto out;
322 }
323 }
Handle the case where the region is been expanded and cannot be moved
329 ret = -ENOMEM;
330 if (flags & MREMAP_MAYMOVE) {
331 if (!(flags & MREMAP_FIXED)) {
332 unsigned long map_flags = 0;
333 if (vma->vm_flags & VM_SHARED)
334 map_flags |= MAP_SHARED;
335
336 new_addr = get_unmapped_area(vma->vm_file, 0,
new_len, vma->vm_pgoff, map_flags);
337 ret = new_addr;
338 if (new_addr & ~PAGE_MASK)
339 goto out;
340 }
341 ret = move_vma(vma, addr, old_len, new_len, new_addr);
342 }
343 out:
344 return ret;
345 }
To expand the region, a new one has to be allocated and the old one moved to it
The call graph for this function is shown in Figure 4.8. This function is responsible for moving all the page table entries from one VMA to another region. If necessary a new VMA will be allocated for the region being moved to. Just like the function above, it is very long but may be broken up into the following distinct parts.
125 static inline unsigned long move_vma(struct vm_area_struct * vma,
126 unsigned long addr, unsigned long old_len, unsigned long new_len,
127 unsigned long new_addr)
128 {
129 struct mm_struct * mm = vma->vm_mm;
130 struct vm_area_struct * new_vma, * next, * prev;
131 int allocated_vma;
132
133 new_vma = NULL;
134 next = find_vma_prev(mm, new_addr, &prev);
135 if (next) {
136 if (prev && prev->vm_end == new_addr &&
137 can_vma_merge(prev, vma->vm_flags) &&
!vma->vm_file && !(vma->vm_flags & VM_SHARED)) {
138 spin_lock(&mm->page_table_lock);
139 prev->vm_end = new_addr + new_len;
140 spin_unlock(&mm->page_table_lock);
141 new_vma = prev;
142 if (next != prev->vm_next)
143 BUG();
144 if (prev->vm_end == next->vm_start &&
can_vma_merge(next, prev->vm_flags)) {
145 spin_lock(&mm->page_table_lock);
146 prev->vm_end = next->vm_end;
147 __vma_unlink(mm, next, prev);
148 spin_unlock(&mm->page_table_lock);
149
150 mm->map_count--;
151 kmem_cache_free(vm_area_cachep, next);
152 }
153 } else if (next->vm_start == new_addr + new_len &&
154 can_vma_merge(next, vma->vm_flags) &&
!vma->vm_file && !(vma->vm_flags & VM_SHARED)) {
155 spin_lock(&mm->page_table_lock);
156 next->vm_start = new_addr;
157 spin_unlock(&mm->page_table_lock);
158 new_vma = next;
159 }
160 } else {
In this block, the new location is between two existing VMAs. Checks are made to see can be preceding region be expanded to cover the new mapping and then if it can be expanded to cover the next VMA as well. If it cannot be expanded, the next region is checked to see if it can be expanded backwards.
161 prev = find_vma(mm, new_addr-1);
162 if (prev && prev->vm_end == new_addr &&
163 can_vma_merge(prev, vma->vm_flags) && !vma->vm_file &&
!(vma->vm_flags & VM_SHARED)) {
164 spin_lock(&mm->page_table_lock);
165 prev->vm_end = new_addr + new_len;
166 spin_unlock(&mm->page_table_lock);
167 new_vma = prev;
168 }
169 }
This block is for the case where the newly mapped region is the last VMA (next is NULL) so a check is made to see can the preceding region be expanded.
170
171 allocated_vma = 0;
172 if (!new_vma) {
173 new_vma = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
174 if (!new_vma)
175 goto out;
176 allocated_vma = 1;
177 }
178
179 if (!move_page_tables(current->mm, new_addr, addr, old_len)) {
180 unsigned long vm_locked = vma->vm_flags & VM_LOCKED;
181
182 if (allocated_vma) {
183 *new_vma = *vma;
184 new_vma->vm_start = new_addr;
185 new_vma->vm_end = new_addr+new_len;
186 new_vma->vm_pgoff +=
(addr-vma->vm_start) >> PAGE_SHIFT;
187 new_vma->vm_raend = 0;
188 if (new_vma->vm_file)
189 get_file(new_vma->vm_file);
190 if (new_vma->vm_ops && new_vma->vm_ops->open)
191 new_vma->vm_ops->open(new_vma);
192 insert_vm_struct(current->mm, new_vma);
193 }
do_munmap(current->mm, addr, old_len);
197 current->mm->total_vm += new_len >> PAGE_SHIFT;
198 if (new_vma->vm_flags & VM_LOCKED) {
199 current->mm->locked_vm += new_len >> PAGE_SHIFT;
200 make_pages_present(new_vma->vm_start,
201 new_vma->vm_end);
202 }
203 return new_addr;
204 }
205 if (allocated_vma)
206 kmem_cache_free(vm_area_cachep, new_vma);
207 out:
208 return -ENOMEM;
209 }
This function makes all pages between addr and end present. It assumes that the two addresses are within the one VMA.
1460 int make_pages_present(unsigned long addr, unsigned long end)
1461 {
1462 int ret, len, write;
1463 struct vm_area_struct * vma;
1464
1465 vma = find_vma(current->mm, addr);
1466 write = (vma->vm_flags & VM_WRITE) != 0;
1467 if (addr >= end)
1468 BUG();
1469 if (end > vma->vm_end)
1470 BUG();
1471 len = (end+PAGE_SIZE-1)/PAGE_SIZE-addr/PAGE_SIZE;
1472 ret = get_user_pages(current, current->mm, addr,
1473 len, write, 0, NULL, NULL);
1474 return ret == len ? 0 : -1;
1475 }
This function is used to fault in user pages and may be used to fault in pages belonging to another process, which is required by ptrace() for example.
454 int get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start,
455 int len, int write, int force, struct page **pages,
struct vm_area_struct **vmas)
456 {
457 int i;
458 unsigned int flags;
459
460 /*
461 * Require read or write permissions.
462 * If 'force' is set, we only require the "MAY" flags.
463 */
464 flags = write ? (VM_WRITE | VM_MAYWRITE) : (VM_READ | VM_MAYREAD);
465 flags &= force ? (VM_MAYREAD | VM_MAYWRITE) : (VM_READ | VM_WRITE);
466 i = 0;
467
468 do {
469 struct vm_area_struct * vma;
470
471 vma = find_extend_vma(mm, start);
472
473 if ( !vma ||
(pages && vma->vm_flags & VM_IO) ||
!(flags & vma->vm_flags) )
474 return i ? : -EFAULT;
475
476 spin_lock(&mm->page_table_lock);
477 do {
478 struct page *map;
479 while (!(map = follow_page(mm, start, write))) {
480 spin_unlock(&mm->page_table_lock);
481 switch (handle_mm_fault(mm, vma, start, write)) {
482 case 1:
483 tsk->min_flt++;
484 break;
485 case 2:
486 tsk->maj_flt++;
487 break;
488 case 0:
489 if (i) return i;
490 return -EFAULT;
491 default:
492 if (i) return i;
493 return -ENOMEM;
494 }
495 spin_lock(&mm->page_table_lock);
496 }
497 if (pages) {
498 pages[i] = get_page_map(map);
499 /* FIXME: call the correct function,
500 * depending on the type of the found page
501 */
502 if (!pages[i])
503 goto bad_page;
504 page_cache_get(pages[i]);
505 }
506 if (vmas)
507 vmas[i] = vma;
508 i++;
509 start += PAGE_SIZE;
510 len--;
511 } while(len && start < vma->vm_end);
512 spin_unlock(&mm->page_table_lock);
513 } while(len);
514 out:
515 return i;
516 517 /* 518 * We found an invalid page in the VMA. Release all we have 519 * so far and fail. 520 */ 521 bad_page: 522 spin_unlock(&mm->page_table_lock); 523 while (i--) 524 page_cache_release(pages[i]); 525 i = -EFAULT; 526 goto out; 527 }
The call graph for this function is shown in Figure 4.9. This function is responsible copying all the page table entries from the region pointed to be old_addr to new_addr. It works by literally copying page table entries one at a time. When it is finished, it deletes all the entries from the old area. This is not the most efficient way to perform the operation, but it is very easy to error recover.
90 static int move_page_tables(struct mm_struct * mm,
91 unsigned long new_addr, unsigned long old_addr,
unsigned long len)
92 {
93 unsigned long offset = len;
94
95 flush_cache_range(mm, old_addr, old_addr + len);
96
102 while (offset) {
103 offset -= PAGE_SIZE;
104 if (move_one_page(mm, old_addr + offset, new_addr +
offset))
105 goto oops_we_failed;
106 }
107 flush_tlb_range(mm, old_addr, old_addr + len);
108 return 0;
109
117 oops_we_failed:
118 flush_cache_range(mm, new_addr, new_addr + len);
119 while ((offset += PAGE_SIZE) < len)
120 move_one_page(mm, new_addr + offset, old_addr + offset);
121 zap_page_range(mm, new_addr, len);
122 return -1;
123 }
This function is responsible for acquiring the spinlock before finding the correct PTE with get_one_pte() and copying it with copy_one_pte()
77 static int move_one_page(struct mm_struct *mm,
unsigned long old_addr, unsigned long new_addr)
78 {
79 int error = 0;
80 pte_t * src;
81
82 spin_lock(&mm->page_table_lock);
83 src = get_one_pte(mm, old_addr);
84 if (src)
85 error = copy_one_pte(mm, src, alloc_one_pte(mm, new_addr));
86 spin_unlock(&mm->page_table_lock);
87 return error;
88 }
This is a very simple page table walk.
18 static inline pte_t *get_one_pte(struct mm_struct *mm,
unsigned long addr)
19 {
20 pgd_t * pgd;
21 pmd_t * pmd;
22 pte_t * pte = NULL;
23
24 pgd = pgd_offset(mm, addr);
25 if (pgd_none(*pgd))
26 goto end;
27 if (pgd_bad(*pgd)) {
28 pgd_ERROR(*pgd);
29 pgd_clear(pgd);
30 goto end;
31 }
32
33 pmd = pmd_offset(pgd, addr);
34 if (pmd_none(*pmd))
35 goto end;
36 if (pmd_bad(*pmd)) {
37 pmd_ERROR(*pmd);
38 pmd_clear(pmd);
39 goto end;
40 }
41
42 pte = pte_offset(pmd, addr);
43 if (pte_none(*pte))
44 pte = NULL;
45 end:
46 return pte;
47 }
Trivial function to allocate what is necessary for one PTE in a region.
49 static inline pte_t *alloc_one_pte(struct mm_struct *mm,
unsigned long addr)
50 {
51 pmd_t * pmd;
52 pte_t * pte = NULL;
53
54 pmd = pmd_alloc(mm, pgd_offset(mm, addr), addr);
55 if (pmd)
56 pte = pte_alloc(mm, pmd, addr);
57 return pte;
58 }
Copies the contents of one PTE to another.
60 static inline int copy_one_pte(struct mm_struct *mm,
pte_t * src, pte_t * dst)
61 {
62 int error = 0;
63 pte_t pte;
64
65 if (!pte_none(*src)) {
66 pte = ptep_get_and_clear(src);
67 if (!dst) {
68 /* No dest? We must put it back. */
69 dst = src;
70 error++;
71 }
72 set_pte(dst, pte);
73 }
74 return error;
75 }
The call graph for this function is shown in Figure 4.11. This function is responsible for unmapping a region. If necessary, the unmapping can span multiple VMAs and it can partially unmap one if necessary. Hence the full unmapping operation is divided into two major operations. This function is responsible for finding what VMAs are affected and unmap_fixup() is responsible for fixing up the remaining VMAs.
This function is divided up in a number of small sections will be dealt with in turn. The are broadly speaking;
924 int do_munmap(struct mm_struct *mm, unsigned long addr,
size_t len)
925 {
926 struct vm_area_struct *mpnt, *prev, **npp, *free, *extra;
927
928 if ((addr & ~PAGE_MASK) || addr > TASK_SIZE ||
len > TASK_SIZE-addr)
929 return -EINVAL;
930
931 if ((len = PAGE_ALIGN(len)) == 0)
932 return -EINVAL;
933
939 mpnt = find_vma_prev(mm, addr, &prev);
940 if (!mpnt)
941 return 0;
942 /* we have addr < mpnt->vm_end */
943
944 if (mpnt->vm_start >= addr+len)
945 return 0;
946
948 if ((mpnt->vm_start < addr && mpnt->vm_end > addr+len)
949 && mm->map_count >= max_map_count)
950 return -ENOMEM;
951
956 extra = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
957 if (!extra)
958 return -ENOMEM;
960 npp = (prev ? &prev->vm_next : &mm->mmap);
961 free = NULL;
962 spin_lock(&mm->page_table_lock);
963 for ( ; mpnt && mpnt->vm_start < addr+len; mpnt = *npp) {
964 *npp = mpnt->vm_next;
965 mpnt->vm_next = free;
966 free = mpnt;
967 rb_erase(&mpnt->vm_rb, &mm->mm_rb);
968 }
969 mm->mmap_cache = NULL; /* Kill the cache. */
970 spin_unlock(&mm->page_table_lock);
This section takes all the VMAs affected by the unmapping and places them on a separate linked list headed by a variable called free. This makes the fixup of the regions much easier.
971
972 /* Ok - we have the memory areas we should free on the
973 * 'free' list, so release them, and unmap the page range..
974 * If the one of the segments is only being partially unmapped,
975 * it will put new vm_area_struct(s) into the address space.
976 * In that case we have to be careful with VM_DENYWRITE.
977 */
978 while ((mpnt = free) != NULL) {
979 unsigned long st, end, size;
980 struct file *file = NULL;
981
982 free = free->vm_next;
983
984 st = addr < mpnt->vm_start ? mpnt->vm_start : addr;
985 end = addr+len;
986 end = end > mpnt->vm_end ? mpnt->vm_end : end;
987 size = end - st;
988
989 if (mpnt->vm_flags & VM_DENYWRITE &&
990 (st != mpnt->vm_start || end != mpnt->vm_end) &&
991 (file = mpnt->vm_file) != NULL) {
992 atomic_dec(&file->f_dentry->d_inode->i_writecount);
993 }
994 remove_shared_vm_struct(mpnt);
995 mm->map_count--;
996
997 zap_page_range(mm, st, size);
998
999 /*
1000 * Fix the mapping, and free the old area
* if it wasn't reused.
1001 */
1002 extra = unmap_fixup(mm, mpnt, st, size, extra);
1003 if (file)
1004 atomic_inc(&file->f_dentry->d_inode->i_writecount);
1005 }
1006 validate_mm(mm); 1007 1008 /* Release the extra vma struct if it wasn't used */ 1009 if (extra) 1010 kmem_cache_free(vm_area_cachep, extra); 1011 1012 free_pgtables(mm, prev, addr, addr+len); 1013 1014 return 0; 1015 }
This function fixes up the regions after a block has been unmapped. It is passed a list of VMAs that are affected by the unmapping, the region and length to be unmapped and a spare VMA that may be required to fix up the region if a whole is created. There is four principle cases it handles; The unmapping of a region, partial unmapping from the start to somewhere in the middle, partial unmapping from somewhere in the middle to the end and the creation of a hole in the middle of the region. Each case will be taken in turn.
787 static struct vm_area_struct * unmap_fixup(struct mm_struct *mm,
788 struct vm_area_struct *area, unsigned long addr, size_t len,
789 struct vm_area_struct *extra)
790 {
791 struct vm_area_struct *mpnt;
792 unsigned long end = addr + len;
793
794 area->vm_mm->total_vm -= len >> PAGE_SHIFT;
795 if (area->vm_flags & VM_LOCKED)
796 area->vm_mm->locked_vm -= len >> PAGE_SHIFT;
797
Function preamble.
798 /* Unmapping the whole area. */
799 if (addr == area->vm_start && end == area->vm_end) {
800 if (area->vm_ops && area->vm_ops->close)
801 area->vm_ops->close(area);
802 if (area->vm_file)
803 fput(area->vm_file);
804 kmem_cache_free(vm_area_cachep, area);
805 return extra;
806 }
The first, and easiest, case is where the full region is being unmapped
809 if (end == area->vm_end) {
810 /*
811 * here area isn't visible to the semaphore-less readers
812 * so we don't need to update it under the spinlock.
813 */
814 area->vm_end = addr;
815 lock_vma_mappings(area);
816 spin_lock(&mm->page_table_lock);
817 }
Handle the case where the middle of the region to the end is been unmapped
817 else if (addr == area->vm_start) {
818 area->vm_pgoff += (end - area->vm_start) >> PAGE_SHIFT;
819 /* same locking considerations of the above case */
820 area->vm_start = end;
821 lock_vma_mappings(area);
822 spin_lock(&mm->page_table_lock);
823 } else {
Handle the case where the VMA is been unmapped from the start to some part in the middle
823 } else {
825 /* Add end mapping -- leave beginning for below */
826 mpnt = extra;
827 extra = NULL;
828
829 mpnt->vm_mm = area->vm_mm;
830 mpnt->vm_start = end;
831 mpnt->vm_end = area->vm_end;
832 mpnt->vm_page_prot = area->vm_page_prot;
833 mpnt->vm_flags = area->vm_flags;
834 mpnt->vm_raend = 0;
835 mpnt->vm_ops = area->vm_ops;
836 mpnt->vm_pgoff = area->vm_pgoff +
((end - area->vm_start) >> PAGE_SHIFT);
837 mpnt->vm_file = area->vm_file;
838 mpnt->vm_private_data = area->vm_private_data;
839 if (mpnt->vm_file)
840 get_file(mpnt->vm_file);
841 if (mpnt->vm_ops && mpnt->vm_ops->open)
842 mpnt->vm_ops->open(mpnt);
843 area->vm_end = addr; /* Truncate area */
844
845 /* Because mpnt->vm_file == area->vm_file this locks
846 * things correctly.
847 */
848 lock_vma_mappings(area);
849 spin_lock(&mm->page_table_lock);
850 __insert_vm_struct(mm, mpnt);
851 }
Handle the case where a hole is being created by a partial unmapping. In this case, the extra VMA is required to create a new mapping from the end of the unmapped region to the end of the old VMA
852 853 __insert_vm_struct(mm, area); 854 spin_unlock(&mm->page_table_lock); 855 unlock_vma_mappings(area); 856 return extra; 857 }
This function simply steps through all VMAs associated with the supplied mm and unmaps them.
1127 void exit_mmap(struct mm_struct * mm)
1128 {
1129 struct vm_area_struct * mpnt;
1130
1131 release_segments(mm);
1132 spin_lock(&mm->page_table_lock);
1133 mpnt = mm->mmap;
1134 mm->mmap = mm->mmap_cache = NULL;
1135 mm->mm_rb = RB_ROOT;
1136 mm->rss = 0;
1137 spin_unlock(&mm->page_table_lock);
1138 mm->total_vm = 0;
1139 mm->locked_vm = 0;
1140
1141 flush_cache_mm(mm);
1142 while (mpnt) {
1143 struct vm_area_struct * next = mpnt->vm_next;
1144 unsigned long start = mpnt->vm_start;
1145 unsigned long end = mpnt->vm_end;
1146 unsigned long size = end - start;
1147
1148 if (mpnt->vm_ops) {
1149 if (mpnt->vm_ops->close)
1150 mpnt->vm_ops->close(mpnt);
1151 }
1152 mm->map_count--;
1153 remove_shared_vm_struct(mpnt);
1154 zap_page_range(mm, start, size);
1155 if (mpnt->vm_file)
1156 fput(mpnt->vm_file);
1157 kmem_cache_free(vm_area_cachep, mpnt);
1158 mpnt = next;
1159 }
1160 flush_tlb_mm(mm);
1161
1162 /* This is just debugging */
1163 if (mm->map_count)
1164 BUG();
1165
1166 clear_page_tables(mm, FIRST_USER_PGD_NR, USER_PTRS_PER_PGD);
1167 }
This is the top-level function used to unmap all PTEs and free pages within a region. It is used when pagetables needs to be torn down such as when the process exits or a region is unmapped.
146 void clear_page_tables(struct mm_struct *mm,
unsigned long first, int nr)
147 {
148 pgd_t * page_dir = mm->pgd;
149
150 spin_lock(&mm->page_table_lock);
151 page_dir += first;
152 do {
153 free_one_pgd(page_dir);
154 page_dir++;
155 } while (--nr);
156 spin_unlock(&mm->page_table_lock);
157
158 /* keep the page table cache within bounds */
159 check_pgt_cache();
160 }
This function tears down one PGD. For each PMD in this PGD, free_one_pmd() will be called.
109 static inline void free_one_pgd(pgd_t * dir)
110 {
111 int j;
112 pmd_t * pmd;
113
114 if (pgd_none(*dir))
115 return;
116 if (pgd_bad(*dir)) {
117 pgd_ERROR(*dir);
118 pgd_clear(dir);
119 return;
120 }
121 pmd = pmd_offset(dir, 0);
122 pgd_clear(dir);
123 for (j = 0; j < PTRS_PER_PMD ; j++) {
124 prefetchw(pmd+j+(PREFETCH_STRIDE/16));
125 free_one_pmd(pmd+j);
126 }
127 pmd_free(pmd);
128 }
93 static inline void free_one_pmd(pmd_t * dir)
94 {
95 pte_t * pte;
96
97 if (pmd_none(*dir))
98 return;
99 if (pmd_bad(*dir)) {
100 pmd_ERROR(*dir);
101 pmd_clear(dir);
102 return;
103 }
104 pte = pte_offset(dir, 0);
105 pmd_clear(dir);
106 pte_free(pte);
107 }
The functions in this section deal with searching the virtual address space for mapped and free regions.
661 struct vm_area_struct * find_vma(struct mm_struct * mm,
unsigned long addr)
662 {
663 struct vm_area_struct *vma = NULL;
664
665 if (mm) {
666 /* Check the cache first. */
667 /* (Cache hit rate is typically around 35%.) */
668 vma = mm->mmap_cache;
669 if (!(vma && vma->vm_end > addr &&
vma->vm_start <= addr)) {
670 rb_node_t * rb_node;
671
672 rb_node = mm->mm_rb.rb_node;
673 vma = NULL;
674
675 while (rb_node) {
676 struct vm_area_struct * vma_tmp;
677
678 vma_tmp = rb_entry(rb_node,
struct vm_area_struct, vm_rb);
679
680 if (vma_tmp->vm_end > addr) {
681 vma = vma_tmp;
682 if (vma_tmp->vm_start <= addr)
683 break;
684 rb_node = rb_node->rb_left;
685 } else
686 rb_node = rb_node->rb_right;
687 }
688 if (vma)
689 mm->mmap_cache = vma;
690 }
691 }
692 return vma;
693 }
696 struct vm_area_struct * find_vma_prev(struct mm_struct * mm,
unsigned long addr,
697 struct vm_area_struct **pprev)
698 {
699 if (mm) {
700 /* Go through the RB tree quickly. */
701 struct vm_area_struct * vma;
702 rb_node_t * rb_node, * rb_last_right, * rb_prev;
703
704 rb_node = mm->mm_rb.rb_node;
705 rb_last_right = rb_prev = NULL;
706 vma = NULL;
707
708 while (rb_node) {
709 struct vm_area_struct * vma_tmp;
710
711 vma_tmp = rb_entry(rb_node,
struct vm_area_struct, vm_rb);
712
713 if (vma_tmp->vm_end > addr) {
714 vma = vma_tmp;
715 rb_prev = rb_last_right;
716 if (vma_tmp->vm_start <= addr)
717 break;
718 rb_node = rb_node->rb_left;
719 } else {
720 rb_last_right = rb_node;
721 rb_node = rb_node->rb_right;
722 }
723 }
724 if (vma) {
725 if (vma->vm_rb.rb_left) {
726 rb_prev = vma->vm_rb.rb_left;
727 while (rb_prev->rb_right)
728 rb_prev = rb_prev->rb_right;
729 }
730 *pprev = NULL;
731 if (rb_prev)
732 *pprev = rb_entry(rb_prev, struct
vm_area_struct, vm_rb);
733 if ((rb_prev ? (*pprev)->vm_next : mm->mmap) !=
vma)
734 BUG();
735 return vma;
736 }
737 }
738 *pprev = NULL;
739 return NULL;
740 }
673 static inline struct vm_area_struct * find_vma_intersection(
struct mm_struct * mm,
unsigned long start_addr, unsigned long end_addr)
674 {
675 struct vm_area_struct * vma = find_vma(mm,start_addr);
676
677 if (vma && end_addr <= vma->vm_start)
678 vma = NULL;
679 return vma;
680 }
The call graph for this function is shown at Figure 4.5.
644 unsigned long get_unmapped_area(struct file *file,
unsigned long addr,
unsigned long len,
unsigned long pgoff,
unsigned long flags)
645 {
646 if (flags & MAP_FIXED) {
647 if (addr > TASK_SIZE - len)
648 return -ENOMEM;
649 if (addr & ~PAGE_MASK)
650 return -EINVAL;
651 return addr;
652 }
653
654 if (file && file->f_op && file->f_op->get_unmapped_area)
655 return file->f_op->get_unmapped_area(file, addr,
len, pgoff, flags);
656
657 return arch_get_unmapped_area(file, addr, len, pgoff, flags);
658 }
Architectures have the option of specifying this function for themselves by defining HAVE_ARCH_UNMAPPED_AREA. If the architectures does not supply one, this version is used.
614 #ifndef HAVE_ARCH_UNMAPPED_AREA
615 static inline unsigned long arch_get_unmapped_area(
struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
616 {
617 struct vm_area_struct *vma;
618
619 if (len > TASK_SIZE)
620 return -ENOMEM;
621
622 if (addr) {
623 addr = PAGE_ALIGN(addr);
624 vma = find_vma(current->mm, addr);
625 if (TASK_SIZE - len >= addr &&
626 (!vma || addr + len <= vma->vm_start))
627 return addr;
628 }
629 addr = PAGE_ALIGN(TASK_UNMAPPED_BASE);
630
631 for (vma = find_vma(current->mm, addr); ; vma = vma->vm_next) {
632 /* At this point: (!vma || addr < vma->vm_end). */
633 if (TASK_SIZE - len < addr)
634 return -ENOMEM;
635 if (!vma || addr + len <= vma->vm_start)
636 return addr;
637 addr = vma->vm_end;
638 }
639 }
640 #else
641 extern unsigned long arch_get_unmapped_area(struct file *,
unsigned long, unsigned long,
unsigned long, unsigned long);
642 #endif
This section contains the functions related to locking and unlocking a region. The main complexity in them is how the regions need to be fixed up after the operation takes place.
The call graph for this function is shown in Figure 4.10. This is the system call mlock() for locking a region of memory into physical memory. This function simply checks to make sure that process and user limits are not exceeeded and that the region to lock is page aligned.
195 asmlinkage long sys_mlock(unsigned long start, size_t len)
196 {
197 unsigned long locked;
198 unsigned long lock_limit;
199 int error = -ENOMEM;
200
201 down_write(¤t->mm->mmap_sem);
202 len = PAGE_ALIGN(len + (start & ~PAGE_MASK));
203 start &= PAGE_MASK;
204
205 locked = len >> PAGE_SHIFT;
206 locked += current->mm->locked_vm;
207
208 lock_limit = current->rlim[RLIMIT_MEMLOCK].rlim_cur;
209 lock_limit >>= PAGE_SHIFT;
210
211 /* check against resource limits */
212 if (locked > lock_limit)
213 goto out;
214
215 /* we may lock at most half of physical memory... */
216 /* (this check is pretty bogus, but doesn't hurt) */
217 if (locked > num_physpages/2)
218 goto out;
219
220 error = do_mlock(start, len, 1);
221 out:
222 up_write(¤t->mm->mmap_sem);
223 return error;
224 }
This is the system call mlockall() which attempts to lock all pages in the calling process in memory. If MCL_CURRENT is specified, all current pages will be locked. If MCL_FUTURE is specified, all future mappings will be locked. The flags may be or-ed together. This function makes sure that the flags and process limits are ok before calling do_mlockall().
266 asmlinkage long sys_mlockall(int flags)
267 {
268 unsigned long lock_limit;
269 int ret = -EINVAL;
270
271 down_write(¤t->mm->mmap_sem);
272 if (!flags || (flags & ~(MCL_CURRENT | MCL_FUTURE)))
273 goto out;
274
275 lock_limit = current->rlim[RLIMIT_MEMLOCK].rlim_cur;
276 lock_limit >>= PAGE_SHIFT;
277
278 ret = -ENOMEM;
279 if (current->mm->total_vm > lock_limit)
280 goto out;
281
282 /* we may lock at most half of physical memory... */
283 /* (this check is pretty bogus, but doesn't hurt) */
284 if (current->mm->total_vm > num_physpages/2)
285 goto out;
286
287 ret = do_mlockall(flags);
288 out:
289 up_write(¤t->mm->mmap_sem);
290 return ret;
291 }
238 static int do_mlockall(int flags)
239 {
240 int error;
241 unsigned int def_flags;
242 struct vm_area_struct * vma;
243
244 if (!capable(CAP_IPC_LOCK))
245 return -EPERM;
246
247 def_flags = 0;
248 if (flags & MCL_FUTURE)
249 def_flags = VM_LOCKED;
250 current->mm->def_flags = def_flags;
251
252 error = 0;
253 for (vma = current->mm->mmap; vma ; vma = vma->vm_next) {
254 unsigned int newflags;
255
256 newflags = vma->vm_flags | VM_LOCKED;
257 if (!(flags & MCL_CURRENT))
258 newflags &= ~VM_LOCKED;
259 error = mlock_fixup(vma, vma->vm_start, vma->vm_end,
newflags);
260 if (error)
261 break;
262 }
263 return error;
264 }
This function is is responsible for starting the work needed to either lock or unlock a region depending on the value of the on parameter. It is broken up into two sections. The first makes sure the region is page aligned (despite the fact the only two callers of this function do the same thing) before finding the VMA that is to be adjusted. The second part then sets the appropriate flags before calling mlock_fixup() for each VMA that is affected by this locking.
148 static int do_mlock(unsigned long start, size_t len, int on)
149 {
150 unsigned long nstart, end, tmp;
151 struct vm_area_struct * vma, * next;
152 int error;
153
154 if (on && !capable(CAP_IPC_LOCK))
155 return -EPERM;
156 len = PAGE_ALIGN(len);
157 end = start + len;
158 if (end < start)
159 return -EINVAL;
160 if (end == start)
161 return 0;
162 vma = find_vma(current->mm, start);
163 if (!vma || vma->vm_start > start)
164 return -ENOMEM;
Page align the request and find the VMA
166 for (nstart = start ; ; ) {
167 unsigned int newflags;
168
170
171 newflags = vma->vm_flags | VM_LOCKED;
172 if (!on)
173 newflags &= ~VM_LOCKED;
174
175 if (vma->vm_end >= end) {
176 error = mlock_fixup(vma, nstart, end, newflags);
177 break;
178 }
179
180 tmp = vma->vm_end;
181 next = vma->vm_next;
182 error = mlock_fixup(vma, nstart, tmp, newflags);
183 if (error)
184 break;
185 nstart = tmp;
186 vma = next;
187 if (!vma || vma->vm_start != nstart) {
188 error = -ENOMEM;
189 break;
190 }
191 }
192 return error;
193 }
Walk through the VMAs affected by this locking and call mlock_fixup() for each of them.
Page align the request before calling do_mlock() which begins the real work of fixing up the regions.
226 asmlinkage long sys_munlock(unsigned long start, size_t len)
227 {
228 int ret;
229
230 down_write(¤t->mm->mmap_sem);
231 len = PAGE_ALIGN(len + (start & ~PAGE_MASK));
232 start &= PAGE_MASK;
233 ret = do_mlock(start, len, 0);
234 up_write(¤t->mm->mmap_sem);
235 return ret;
236 }
Trivial function. If the flags to mlockall() are 0 it gets translated as none of the current pages must be present and no future mappings should be locked either which means the VM_LOCKED flag will be removed on all VMAs.
293 asmlinkage long sys_munlockall(void)
294 {
295 int ret;
296
297 down_write(¤t->mm->mmap_sem);
298 ret = do_mlockall(0);
299 up_write(¤t->mm->mmap_sem);
300 return ret;
301 }
This function identifies four separate types of locking that must be addressed. There first is where the full VMA is to be locked where it calls mlock_fixup_all(). The second is where only the beginning portion of the VMA is affected, handled by mlock_fixup_start(). The third is the locking of a region at the end handled by mlock_fixup_end() and the last is locking a region in the middle of the VMA with mlock_fixup_middle().
117 static int mlock_fixup(struct vm_area_struct * vma,
118 unsigned long start, unsigned long end, unsigned int newflags)
119 {
120 int pages, retval;
121
122 if (newflags == vma->vm_flags)
123 return 0;
124
125 if (start == vma->vm_start) {
126 if (end == vma->vm_end)
127 retval = mlock_fixup_all(vma, newflags);
128 else
129 retval = mlock_fixup_start(vma, end, newflags);
130 } else {
131 if (end == vma->vm_end)
132 retval = mlock_fixup_end(vma, start, newflags);
133 else
134 retval = mlock_fixup_middle(vma, start,
end, newflags);
135 }
136 if (!retval) {
137 /* keep track of amount of locked VM */
138 pages = (end - start) >> PAGE_SHIFT;
139 if (newflags & VM_LOCKED) {
140 pages = -pages;
141 make_pages_present(start, end);
142 }
143 vma->vm_mm->locked_vm -= pages;
144 }
145 return retval;
146 }
15 static inline int mlock_fixup_all(struct vm_area_struct * vma,
int newflags)
16 {
17 spin_lock(&vma->vm_mm->page_table_lock);
18 vma->vm_flags = newflags;
19 spin_unlock(&vma->vm_mm->page_table_lock);
20 return 0;
21 }
Slightly more compilcated. A new VMA is required to represent the affected region. The start of the old VMA is moved forward
23 static inline int mlock_fixup_start(struct vm_area_struct * vma,
24 unsigned long end, int newflags)
25 {
26 struct vm_area_struct * n;
27
28 n = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
29 if (!n)
30 return -EAGAIN;
31 *n = *vma;
32 n->vm_end = end;
33 n->vm_flags = newflags;
34 n->vm_raend = 0;
35 if (n->vm_file)
36 get_file(n->vm_file);
37 if (n->vm_ops && n->vm_ops->open)
38 n->vm_ops->open(n);
39 vma->vm_pgoff += (end - vma->vm_start) >> PAGE_SHIFT;
40 lock_vma_mappings(vma);
41 spin_lock(&vma->vm_mm->page_table_lock);
42 vma->vm_start = end;
43 __insert_vm_struct(current->mm, n);
44 spin_unlock(&vma->vm_mm->page_table_lock);
45 unlock_vma_mappings(vma);
46 return 0;
47 }
Essentially the same as mlock_fixup_start() except the affected region is at the end of the VMA.
49 static inline int mlock_fixup_end(struct vm_area_struct * vma,
50 unsigned long start, int newflags)
51 {
52 struct vm_area_struct * n;
53
54 n = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
55 if (!n)
56 return -EAGAIN;
57 *n = *vma;
58 n->vm_start = start;
59 n->vm_pgoff += (n->vm_start - vma->vm_start) >> PAGE_SHIFT;
60 n->vm_flags = newflags;
61 n->vm_raend = 0;
62 if (n->vm_file)
63 get_file(n->vm_file);
64 if (n->vm_ops && n->vm_ops->open)
65 n->vm_ops->open(n);
66 lock_vma_mappings(vma);
67 spin_lock(&vma->vm_mm->page_table_lock);
68 vma->vm_end = start;
69 __insert_vm_struct(current->mm, n);
70 spin_unlock(&vma->vm_mm->page_table_lock);
71 unlock_vma_mappings(vma);
72 return 0;
73 }
Similar to the previous two fixup functions except that 2 new regions are required to fix up the mapping.
75 static inline int mlock_fixup_middle(struct vm_area_struct * vma,
76 unsigned long start, unsigned long end, int newflags)
77 {
78 struct vm_area_struct * left, * right;
79
80 left = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
81 if (!left)
82 return -EAGAIN;
83 right = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
84 if (!right) {
85 kmem_cache_free(vm_area_cachep, left);
86 return -EAGAIN;
87 }
88 *left = *vma;
89 *right = *vma;
90 left->vm_end = start;
91 right->vm_start = end;
92 right->vm_pgoff += (right->vm_start - left->vm_start) >>
PAGE_SHIFT;
93 vma->vm_flags = newflags;
94 left->vm_raend = 0;
95 right->vm_raend = 0;
96 if (vma->vm_file)
97 atomic_add(2, &vma->vm_file->f_count);
98
99 if (vma->vm_ops && vma->vm_ops->open) {
100 vma->vm_ops->open(left);
101 vma->vm_ops->open(right);
102 }
103 vma->vm_raend = 0;
104 vma->vm_pgoff += (start - vma->vm_start) >> PAGE_SHIFT;
105 lock_vma_mappings(vma);
106 spin_lock(&vma->vm_mm->page_table_lock);
107 vma->vm_start = start;
108 vma->vm_end = end;
109 vma->vm_flags = newflags;
110 __insert_vm_struct(current->mm, left);
111 __insert_vm_struct(current->mm, right);
112 spin_unlock(&vma->vm_mm->page_table_lock);
113 unlock_vma_mappings(vma);
114 return 0;
115 }
This section deals with the page fault handler. It begins with the architecture specific function for the x86 and then moves to the architecture independent layer. The architecture specific functions all have the same responsibilities.
The call graph for this function is shown in Figure 4.12. This function is the x86 architecture dependent function for the handling of page fault exception handlers. Each architecture registers their own but all of them have similar responsibilities.
140 asmlinkage void do_page_fault(struct pt_regs *regs,
unsigned long error_code)
141 {
142 struct task_struct *tsk;
143 struct mm_struct *mm;
144 struct vm_area_struct * vma;
145 unsigned long address;
146 unsigned long page;
147 unsigned long fixup;
148 int write;
149 siginfo_t info;
150
151 /* get the address */
152 __asm__("movl %%cr2,%0":"=r" (address));
153
154 /* It's safe to allow irq's after cr2 has been saved */
155 if (regs->eflags & X86_EFLAGS_IF)
156 local_irq_enable();
157
158 tsk = current;
159
Function preamble. Get the fault address and enable interrupts
173 if (address >= TASK_SIZE && !(error_code & 5)) 174 goto vmalloc_fault; 175 176 mm = tsk->mm; 177 info.si_code = SEGV_MAPERR; 178 183 if (in_interrupt() || !mm) 184 goto no_context; 185
Check for exceptional faults, kernel faults, fault in interrupt and fault with no memory context
186 down_read(&mm->mmap_sem);
187
188 vma = find_vma(mm, address);
189 if (!vma)
190 goto bad_area;
191 if (vma->vm_start <= address)
192 goto good_area;
193 if (!(vma->vm_flags & VM_GROWSDOWN))
194 goto bad_area;
195 if (error_code & 4) {
196 /*
197 * accessing the stack below %esp is always a bug.
198 * The "+ 32" is there due to some instructions (like
199 * pusha) doing post-decrement on the stack and that
200 * doesn't show up until later..
201 */
202 if (address + 32 < regs->esp)
203 goto bad_area;
204 }
205 if (expand_stack(vma, address))
206 goto bad_area;
If a fault in userspace, find the VMA for the faulting address and determine if it is a good area, a bad area or if the fault occurred near a region that can be expanded such as the stack
211 good_area:
212 info.si_code = SEGV_ACCERR;
213 write = 0;
214 switch (error_code & 3) {
215 default: /* 3: write, present */
216 #ifdef TEST_VERIFY_AREA
217 if (regs->cs == KERNEL_CS)
218 printk("WP fault at %08lx\n", regs->eip);
219 #endif
220 /* fall through */
221 case 2: /* write, not present */
222 if (!(vma->vm_flags & VM_WRITE))
223 goto bad_area;
224 write++;
225 break;
226 case 1: /* read, present */
227 goto bad_area;
228 case 0: /* read, not present */
229 if (!(vma->vm_flags & (VM_READ | VM_EXEC)))
230 goto bad_area;
231 }
There is the first part of a good area is handled. The permissions need to be checked in case this is a protection fault.
233 survive:
239 switch (handle_mm_fault(mm, vma, address, write)) {
240 case 1:
241 tsk->min_flt++;
242 break;
243 case 2:
244 tsk->maj_flt++;
245 break;
246 case 0:
247 goto do_sigbus;
248 default:
249 goto out_of_memory;
250 }
251
252 /*
253 * Did it hit the DOS screen memory VA from vm86 mode?
254 */
255 if (regs->eflags & VM_MASK) {
256 unsigned long bit = (address - 0xA0000) >> PAGE_SHIFT;
257 if (bit < 32)
258 tsk->thread.screen_bitmap |= 1 << bit;
259 }
260 up_read(&mm->mmap_sem);
261 return;
At this point, an attempt is going to be made to handle the fault gracefully with handle_mm_fault().
267 bad_area:
268 up_read(&mm->mmap_sem);
269
270 /* User mode accesses just cause a SIGSEGV */
271 if (error_code & 4) {
272 tsk->thread.cr2 = address;
273 tsk->thread.error_code = error_code;
274 tsk->thread.trap_no = 14;
275 info.si_signo = SIGSEGV;
276 info.si_errno = 0;
277 /* info.si_code has been set above */
278 info.si_addr = (void *)address;
279 force_sig_info(SIGSEGV, &info, tsk);
280 return;
281 }
282
283 /*
284 * Pentium F0 0F C7 C8 bug workaround.
285 */
286 if (boot_cpu_data.f00f_bug) {
287 unsigned long nr;
288
289 nr = (address - idt) >> 3;
290
291 if (nr == 6) {
292 do_invalid_op(regs, 0);
293 return;
294 }
295 }
This is the bad area handler such as using memory with no vm_area_struct managing it. If the fault is not by a user process or the f00f bug, the no_context label is fallen through to.
296
297 no_context:
298 /* Are we prepared to handle this kernel fault? */
299 if ((fixup = search_exception_table(regs->eip)) != 0) {
300 regs->eip = fixup;
301 return;
302 }
304 /*
305 * Oops. The kernel tried to access some bad page. We'll have to
306 * terminate things with extreme prejudice.
307 */
308
309 bust_spinlocks(1);
310
311 if (address < PAGE_SIZE)
312 printk(KERN_ALERT "Unable to handle kernel NULL pointer
dereference");
313 else
314 printk(KERN_ALERT "Unable to handle kernel paging
request");
315 printk(" at virtual address %08lx\n",address);
316 printk(" printing eip:\n");
317 printk("%08lx\n", regs->eip);
318 asm("movl %%cr3,%0":"=r" (page));
319 page = ((unsigned long *) __va(page))[address >> 22];
320 printk(KERN_ALERT "*pde = %08lx\n", page);
321 if (page & 1) {
322 page &= PAGE_MASK;
323 address &= 0x003ff000;
324 page = ((unsigned long *)
__va(page))[address >> PAGE_SHIFT];
325 printk(KERN_ALERT "*pte = %08lx\n", page);
326 }
327 die("Oops", regs, error_code);
328 bust_spinlocks(0);
329 do_exit(SIGKILL);
This is the no_context handler. Some bad exception occurred which is going to end up in the process been terminated in all likeliness. Otherwise the kernel faulted when it definitely should have and an OOPS report is generated.
335 out_of_memory:
336 if (tsk->pid == 1) {
337 yield();
338 goto survive;
339 }
340 up_read(&mm->mmap_sem);
341 printk("VM: killing process %s\n", tsk->comm);
342 if (error_code & 4)
343 do_exit(SIGKILL);
344 goto no_context;
The out of memory handler. Usually ends with the faulting process getting killed unless it is init
345 346 do_sigbus: 347 up_read(&mm->mmap_sem); 348 353 tsk->thread.cr2 = address; 354 tsk->thread.error_code = error_code; 355 tsk->thread.trap_no = 14; 356 info.si_signo = SIGBUS; 357 info.si_errno = 0; 358 info.si_code = BUS_ADRERR; 359 info.si_addr = (void *)address; 360 force_sig_info(SIGBUS, &info, tsk); 361 362 /* Kernel mode? Handle exceptions or die */ 363 if (!(error_code & 4)) 364 goto no_context; 365 return;
367 vmalloc_fault:
368 {
376 int offset = __pgd_offset(address);
377 pgd_t *pgd, *pgd_k;
378 pmd_t *pmd, *pmd_k;
379 pte_t *pte_k;
380
381 asm("movl %%cr3,%0":"=r" (pgd));
382 pgd = offset + (pgd_t *)__va(pgd);
383 pgd_k = init_mm.pgd + offset;
384
385 if (!pgd_present(*pgd_k))
386 goto no_context;
387 set_pgd(pgd, *pgd_k);
388
389 pmd = pmd_offset(pgd, address);
390 pmd_k = pmd_offset(pgd_k, address);
391 if (!pmd_present(*pmd_k))
392 goto no_context;
393 set_pmd(pmd, *pmd_k);
394
395 pte_k = pte_offset(pmd_k, address);
396 if (!pte_present(*pte_k))
397 goto no_context;
398 return;
399 }
400 }
This is the vmalloc fault handler. When pages are mapped in the vmalloc space, only the refernce page table is updated. As each process references this area, a fault will be trapped and the process page tables will be synchronised with the reference page table here.
This function is called by the architecture dependant page fault handler. The VMA supplied is guarenteed to be one that can grow to cover the address.
640 static inline int expand_stack(struct vm_area_struct * vma,
unsigned long address)
641 {
642 unsigned long grow;
643
644 /*
645 * vma->vm_start/vm_end cannot change under us because
* the caller is required
646 * to hold the mmap_sem in write mode. We need to get the
647 * spinlock only before relocating the vma range ourself.
648 */
649 address &= PAGE_MASK;
650 spin_lock(&vma->vm_mm->page_table_lock);
651 grow = (vma->vm_start - address) >> PAGE_SHIFT;
652 if (vma->vm_end - address > current->rlim[RLIMIT_STACK].rlim_cur ||
653 ((vma->vm_mm->total_vm + grow) << PAGE_SHIFT) >
current->rlim[RLIMIT_AS].rlim_cur) {
654 spin_unlock(&vma->vm_mm->page_table_lock);
655 return -ENOMEM;
656 }
657 vma->vm_start = address;
658 vma->vm_pgoff -= grow;
659 vma->vm_mm->total_vm += grow;
660 if (vma->vm_flags & VM_LOCKED)
661 vma->vm_mm->locked_vm += grow;
662 spin_unlock(&vma->vm_mm->page_table_lock);
663 return 0;
664 }
This is the top level pair of functions for the architecture independent page fault handler.
The call graph for this function is shown in Figure 4.14. This function allocates the PMD and PTE necessary for this new PTE hat is about to be allocated. It takes the necessary locks to protect the page tables before calling handle_pte_fault() to fault in the page itself.
1364 int handle_mm_fault(struct mm_struct *mm,
struct vm_area_struct * vma,
1365 unsigned long address, int write_access)
1366 {
1367 pgd_t *pgd;
1368 pmd_t *pmd;
1369
1370 current->state = TASK_RUNNING;
1371 pgd = pgd_offset(mm, address);
1372
1373 /*
1374 * We need the page table lock to synchronize with kswapd
1375 * and the SMP-safe atomic PTE updates.
1376 */
1377 spin_lock(&mm->page_table_lock);
1378 pmd = pmd_alloc(mm, pgd, address);
1379
1380 if (pmd) {
1381 pte_t * pte = pte_alloc(mm, pmd, address);
1382 if (pte)
1383 return handle_pte_fault(mm, vma, address,
write_access, pte);
1384 }
1385 spin_unlock(&mm->page_table_lock);
1386 return -1;
1387 }
This function decides what type of fault this is and which function should handle it. do_no_page() is called if this is the first time a page is to be allocated. do_swap_page() handles the case where the page was swapped out to disk with the exception of pages swapped out from tmpfs. do_wp_page() breaks COW pages. If none of them are appropriate, the PTE entry is simply updated. If it was written to, it is marked dirty and it is marked accessed to show it is a young page.
1331 static inline int handle_pte_fault(struct mm_struct *mm,
1332 struct vm_area_struct * vma, unsigned long address,
1333 int write_access, pte_t * pte)
1334 {
1335 pte_t entry;
1336
1337 entry = *pte;
1338 if (!pte_present(entry)) {
1339 /*
1340 * If it truly wasn't present, we know that kswapd
1341 * and the PTE updates will not touch it later. So
1342 * drop the lock.
1343 */
1344 if (pte_none(entry))
1345 return do_no_page(mm, vma, address,
write_access, pte);
1346 return do_swap_page(mm, vma, address, pte, entry,
write_access);
1347 }
1348
1349 if (write_access) {
1350 if (!pte_write(entry))
1351 return do_wp_page(mm, vma, address, pte, entry);
1352
1353 entry = pte_mkdirty(entry);
1354 }
1355 entry = pte_mkyoung(entry);
1356 establish_pte(vma, address, pte, entry);
1357 spin_unlock(&mm->page_table_lock);
1358 return 1;
1359 }
The call graph for this function is shown in Figure 4.15. This function is called the first time a page is referenced so that it may be allocated and filled with data if necessary. If it is an anonymous page, determined by the lack of a vm_ops available to the VMA or the lack of a nopage() function, then do_anonymous_page() is called. Otherwise the supplied nopage() function is called to allocate a page and it is inserted into the page tables here. The function has the following tasks;
1245 static int do_no_page(struct mm_struct * mm,
struct vm_area_struct * vma,
1246 unsigned long address, int write_access, pte_t *page_table)
1247 {
1248 struct page * new_page;
1249 pte_t entry;
1250
1251 if (!vma->vm_ops || !vma->vm_ops->nopage)
1252 return do_anonymous_page(mm, vma, page_table,
write_access, address);
1253 spin_unlock(&mm->page_table_lock);
1254
1255 new_page = vma->vm_ops->nopage(vma, address & PAGE_MASK, 0);
1256
1257 if (new_page == NULL) /* no page was available -- SIGBUS */
1258 return 0;
1259 if (new_page == NOPAGE_OOM)
1260 return -1;
1265 if (write_access && !(vma->vm_flags & VM_SHARED)) {
1266 struct page * page = alloc_page(GFP_HIGHUSER);
1267 if (!page) {
1268 page_cache_release(new_page);
1269 return -1;
1270 }
1271 copy_user_highpage(page, new_page, address);
1272 page_cache_release(new_page);
1273 lru_cache_add(page);
1274 new_page = page;
1275 }
Break COW early in this block if appropriate. COW is broken if the fault is a write fault and the region is not shared with VM_SHARED. If COW was not broken in this case, a second fault would occur immediately upon return.
1277 spin_lock(&mm->page_table_lock);
1288 /* Only go through if we didn't race with anybody else... */
1289 if (pte_none(*page_table)) {
1290 ++mm->rss;
1291 flush_page_to_ram(new_page);
1292 flush_icache_page(vma, new_page);
1293 entry = mk_pte(new_page, vma->vm_page_prot);
1294 if (write_access)
1295 entry = pte_mkwrite(pte_mkdirty(entry));
1296 set_pte(page_table, entry);
1297 } else {
1298 /* One of our sibling threads was faster, back out. */
1299 page_cache_release(new_page);
1300 spin_unlock(&mm->page_table_lock);
1301 return 1;
1302 }
1303
1304 /* no need to invalidate: a not-present page shouldn't
* be cached
*/
1305 update_mmu_cache(vma, address, entry);
1306 spin_unlock(&mm->page_table_lock);
1307 return 2; /* Major fault */
1308 }
This function allocates a new page for a process accessing a page for the first time. If it is a read access, a system wide page containing only zeros is mapped into the process. If it is write, a zero filled page is allocated and placed within the page tables
1190 static int do_anonymous_page(struct mm_struct * mm,
struct vm_area_struct * vma,
pte_t *page_table, int write_access,
unsigned long addr)
1191 {
1192 pte_t entry;
1193
1194 /* Read-only mapping of ZERO_PAGE. */
1195 entry = pte_wrprotect(mk_pte(ZERO_PAGE(addr),
vma->vm_page_prot));
1196
1197 /* ..except if it's a write access */
1198 if (write_access) {
1199 struct page *page;
1200
1201 /* Allocate our own private page. */
1202 spin_unlock(&mm->page_table_lock);
1203
1204 page = alloc_page(GFP_HIGHUSER);
1205 if (!page)
1206 goto no_mem;
1207 clear_user_highpage(page, addr);
1208
1209 spin_lock(&mm->page_table_lock);
1210 if (!pte_none(*page_table)) {
1211 page_cache_release(page);
1212 spin_unlock(&mm->page_table_lock);
1213 return 1;
1214 }
1215 mm->rss++;
1216 flush_page_to_ram(page);
1217 entry = pte_mkwrite(
pte_mkdirty(mk_pte(page, vma->vm_page_prot)));
1218 lru_cache_add(page);
1219 mark_page_accessed(page);
1220 }
1221
1222 set_pte(page_table, entry);
1223
1224 /* No need to invalidate - it was non-present before */
1225 update_mmu_cache(vma, addr, entry);
1226 spin_unlock(&mm->page_table_lock);
1227 return 1; /* Minor fault */
1228
1229 no_mem:
1230 return -1;
1231 }
The call graph for this function is shown in Figure 4.16. This function handles the case where a page has been swapped out. A swapped out page may exist in the swap cache if it is shared between a number of processes or recently swapped in during readahead. This function is broken up into three parts
1117 static int do_swap_page(struct mm_struct * mm,
1118 struct vm_area_struct * vma, unsigned long address,
1119 pte_t * page_table, pte_t orig_pte, int write_access)
1120 {
1121 struct page *page;
1122 swp_entry_t entry = pte_to_swp_entry(orig_pte);
1123 pte_t pte;
1124 int ret = 1;
1125
1126 spin_unlock(&mm->page_table_lock);
1127 page = lookup_swap_cache(entry);
Function preamble, check for the page in the swap cache
1128 if (!page) {
1129 swapin_readahead(entry);
1130 page = read_swap_cache_async(entry);
1131 if (!page) {
1136 int retval;
1137 spin_lock(&mm->page_table_lock);
1138 retval = pte_same(*page_table, orig_pte) ? -1 : 1;
1139 spin_unlock(&mm->page_table_lock);
1140 return retval;
1141 }
1142
1143 /* Had to read the page from swap area: Major fault */
1144 ret = 2;
1145 }
If the page did not exist in the swap cache, then read it from backing storage with swapin_readhead() which reads in the requested pages and a number of pages after it. Once it completes, read_swap_cache_async() should be able to return the page.
1147 mark_page_accessed(page);
1148
1149 lock_page(page);
1150
1151 /*
1152 * Back out if somebody else faulted in this pte while we
1153 * released the page table lock.
1154 */
1155 spin_lock(&mm->page_table_lock);
1156 if (!pte_same(*page_table, orig_pte)) {
1157 spin_unlock(&mm->page_table_lock);
1158 unlock_page(page);
1159 page_cache_release(page);
1160 return 1;
1161 }
1162
1163 /* The page isn't present yet, go ahead with the fault. */
1164
1165 swap_free(entry);
1166 if (vm_swap_full())
1167 remove_exclusive_swap_page(page);
1168
1169 mm->rss++;
1170 pte = mk_pte(page, vma->vm_page_prot);
1171 if (write_access && can_share_swap_page(page))
1172 pte = pte_mkdirty(pte_mkwrite(pte));
1173 unlock_page(page);
1174
1175 flush_page_to_ram(page);
1176 flush_icache_page(vma, page);
1177 set_pte(page_table, pte);
1178
1179 /* No need to invalidate - it was non-present before */
1180 update_mmu_cache(vma, address, pte);
1181 spin_unlock(&mm->page_table_lock);
1182 return ret;
1183 }
Place the page in the process page tables
This function determines if the swap cache entry for this page may be used or not. It may be used if there is no other references to it. Most of the work is performed by exclusive_swap_page() but this function first makes a few basic checks to avoid having to acquire too many locks.
259 int can_share_swap_page(struct page *page)
260 {
261 int retval = 0;
262
263 if (!PageLocked(page))
264 BUG();
265 switch (page_count(page)) {
266 case 3:
267 if (!page->buffers)
268 break;
269 /* Fallthrough */
270 case 2:
271 if (!PageSwapCache(page))
272 break;
273 retval = exclusive_swap_page(page);
274 break;
275 case 1:
276 if (PageReserved(page))
277 break;
278 retval = 1;
279 }
280 return retval;
281 }
This function checks if the process is the only user of a locked swap page.
229 static int exclusive_swap_page(struct page *page)
230 {
231 int retval = 0;
232 struct swap_info_struct * p;
233 swp_entry_t entry;
234
235 entry.val = page->index;
236 p = swap_info_get(entry);
237 if (p) {
238 /* Is the only swap cache user the cache itself? */
239 if (p->swap_map[SWP_OFFSET(entry)] == 1) {
240 /* Recheck the page count with the pagecache
* lock held.. */
241 spin_lock(&pagecache_lock);
242 if (page_count(page) - !!page->buffers == 2)
243 retval = 1;
244 spin_unlock(&pagecache_lock);
245 }
246 swap_info_put(p);
247 }
248 return retval;
249 }
The call graph for this function is shown in Figure 4.17. This function handles the case where a user tries to write to a private page shared amoung processes, such as what happens after fork(). Basically what happens is a page is allocated, the contents copied to the new page and the shared count decremented in the old page.
948 static int do_wp_page(struct mm_struct *mm,
struct vm_area_struct * vma,
949 unsigned long address, pte_t *page_table, pte_t pte)
950 {
951 struct page *old_page, *new_page;
952
953 old_page = pte_page(pte);
954 if (!VALID_PAGE(old_page))
955 goto bad_wp_page;
956
957 if (!TryLockPage(old_page)) {
958 int reuse = can_share_swap_page(old_page);
959 unlock_page(old_page);
960 if (reuse) {
961 flush_cache_page(vma, address);
962 establish_pte(vma, address, page_table,
pte_mkyoung(pte_mkdirty(pte_mkwrite(pte))));
963 spin_unlock(&mm->page_table_lock);
964 return 1; /* Minor fault */
965 }
966 }
968 /* 969 * Ok, we need to copy. Oh, well.. 970 */ 971 page_cache_get(old_page); 972 spin_unlock(&mm->page_table_lock); 973 974 new_page = alloc_page(GFP_HIGHUSER); 975 if (!new_page) 976 goto no_mem; 977 copy_cow_page(old_page,new_page,address); 978
982 spin_lock(&mm->page_table_lock);
983 if (pte_same(*page_table, pte)) {
984 if (PageReserved(old_page))
985 ++mm->rss;
986 break_cow(vma, new_page, address, page_table);
987 lru_cache_add(new_page);
988
989 /* Free the old page.. */
990 new_page = old_page;
991 }
992 spin_unlock(&mm->page_table_lock);
993 page_cache_release(new_page);
994 page_cache_release(old_page);
995 return 1; /* Minor fault */
996
997 bad_wp_page:
998 spin_unlock(&mm->page_table_lock);
999 printk("do_wp_page: bogus page at address %08lx (page 0x%lx)\n",
address,(unsigned long)old_page);
1000 return -1;
1001 no_mem:
1002 page_cache_release(old_page);
1003 return -1;
1004 }
This is more the domain of the IO manager than the VM but because it performs the operations via the page cache, we will cover it briefly. The operation of generic_file_write() is essentially the same although it is not covered by this book. However, if you understand how the read takes place, the write function will pose no problem to you.
This is the generic file read function used by any filesystem that reads pages through the page cache. For normal IO, it is responsible for building a read_descriptor_t for use with do_generic_file_read() and file_read_actor(). For direct IO, this function is basically a wrapper around generic_file_direct_IO().
1695 ssize_t generic_file_read(struct file * filp,
char * buf, size_t count,
loff_t *ppos)
1696 {
1697 ssize_t retval;
1698
1699 if ((ssize_t) count < 0)
1700 return -EINVAL;
1701
1702 if (filp->f_flags & O_DIRECT)
1703 goto o_direct;
1704
1705 retval = -EFAULT;
1706 if (access_ok(VERIFY_WRITE, buf, count)) {
1707 retval = 0;
1708
1709 if (count) {
1710 read_descriptor_t desc;
1711
1712 desc.written = 0;
1713 desc.count = count;
1714 desc.buf = buf;
1715 desc.error = 0;
1716 do_generic_file_read(filp, ppos, &desc,
file_read_actor);
1717
1718 retval = desc.written;
1719 if (!retval)
1720 retval = desc.error;
1721 }
1722 }
1723 out:
1724 return retval;
This block is concern with normal file IO.
1725
1726 o_direct:
1727 {
1728 loff_t pos = *ppos, size;
1729 struct address_space *mapping =
filp->f_dentry->d_inode->i_mapping;
1730 struct inode *inode = mapping->host;
1731
1732 retval = 0;
1733 if (!count)
1734 goto out; /* skip atime */
1735 down_read(&inode->i_alloc_sem);
1736 down(&inode->i_sem);
1737 size = inode->i_size;
1738 if (pos < size) {
1739 retval = generic_file_direct_IO(READ, filp, buf,
count, pos);
1740 if (retval > 0)
1741 *ppos = pos + retval;
1742 }
1743 UPDATE_ATIME(filp->f_dentry->d_inode);
1744 goto out;
1745 }
1746 }
This block is concerned with direct IO. It is largely responsible for extracting the parameters required for generic_file_direct_IO().
This is the core part of the generic file read operation. It is responsible for allocating a page if it doesn't already exist in the page cache. If it does, it must make sure the page is up-to-date and finally, it is responsible for making sure that the appropriate readahead window is set.
1349 void do_generic_file_read(struct file * filp,
loff_t *ppos,
read_descriptor_t * desc,
read_actor_t actor)
1350 {
1351 struct address_space *mapping =
filp->f_dentry->d_inode->i_mapping;
1352 struct inode *inode = mapping->host;
1353 unsigned long index, offset;
1354 struct page *cached_page;
1355 int reada_ok;
1356 int error;
1357 int max_readahead = get_max_readahead(inode);
1358
1359 cached_page = NULL;
1360 index = *ppos >> PAGE_CACHE_SHIFT;
1361 offset = *ppos & ~PAGE_CACHE_MASK;
1362
1363 /*
1364 * If the current position is outside the previous read-ahead
1365 * window, we reset the current read-ahead context and set read
1366 * ahead max to zero (will be set to just needed value later),
1367 * otherwise, we assume that the file accesses are sequential
1368 * enough to continue read-ahead.
1369 */
1370 if (index > filp->f_raend ||
index + filp->f_rawin < filp->f_raend) {
1371 reada_ok = 0;
1372 filp->f_raend = 0;
1373 filp->f_ralen = 0;
1374 filp->f_ramax = 0;
1375 filp->f_rawin = 0;
1376 } else {
1377 reada_ok = 1;
1378 }
1379 /*
1380 * Adjust the current value of read-ahead max.
1381 * If the read operation stay in the first half page, force no
1382 * readahead. Otherwise try to increase read ahead max just
* enough to do the read request.
1383 * Then, at least MIN_READAHEAD if read ahead is ok,
1384 * and at most MAX_READAHEAD in all cases.
1385 */
1386 if (!index && offset + desc->count <= (PAGE_CACHE_SIZE >> 1)) {
1387 filp->f_ramax = 0;
1388 } else {
1389 unsigned long needed;
1390
1391 needed = ((offset + desc->count) >> PAGE_CACHE_SHIFT) + 1;
1392
1393 if (filp->f_ramax < needed)
1394 filp->f_ramax = needed;
1395
1396 if (reada_ok && filp->f_ramax < vm_min_readahead)
1397 filp->f_ramax = vm_min_readahead;
1398 if (filp->f_ramax > max_readahead)
1399 filp->f_ramax = max_readahead;
1400 }
1402 for (;;) {
1403 struct page *page, **hash;
1404 unsigned long end_index, nr, ret;
1405
1406 end_index = inode->i_size >> PAGE_CACHE_SHIFT;
1407
1408 if (index > end_index)
1409 break;
1410 nr = PAGE_CACHE_SIZE;
1411 if (index == end_index) {
1412 nr = inode->i_size & ~PAGE_CACHE_MASK;
1413 if (nr <= offset)
1414 break;
1415 }
1416
1417 nr = nr - offset;
1418
1419 /*
1420 * Try to find the data in the page cache..
1421 */
1422 hash = page_hash(mapping, index);
1423
1424 spin_lock(&pagecache_lock);
1425 page = __find_page_nolock(mapping, index, *hash);
1426 if (!page)
1427 goto no_cached_page;
1428 found_page: 1429 page_cache_get(page); 1430 spin_unlock(&pagecache_lock); 1431 1432 if (!Page_Uptodate(page)) 1433 goto page_not_up_to_date; 1434 generic_file_readahead(reada_ok, filp, inode, page);
In this block, the page was found in the page cache.
1435 page_ok: 1436 /* If users can be writing to this page using arbitrary 1437 * virtual addresses, take care about potential aliasing 1438 * before reading the page on the kernel side. 1439 */ 1440 if (mapping->i_mmap_shared != NULL) 1441 flush_dcache_page(page); 1442 1443 /* 1444 * Mark the page accessed if we read the 1445 * beginning or we just did an lseek. 1446 */ 1447 if (!offset || !filp->f_reada) 1448 mark_page_accessed(page); 1449 1450 /* 1451 * Ok, we have the page, and it's up-to-date, so 1452 * now we can copy it to user space... 1453 * 1454 * The actor routine returns how many bytes were actually used.. 1455 * NOTE! This may not be the same as how much of a user buffer 1456 * we filled up (we may be padding etc), so we can only update 1457 * "pos" here (the actor routine has to update the user buffer 1458 * pointers and the remaining count). 1459 */ 1460 ret = actor(desc, page, offset, nr); 1461 offset += ret; 1462 index += offset >> PAGE_CACHE_SHIFT; 1463 offset &= ~PAGE_CACHE_MASK; 1464 1465 page_cache_release(page); 1466 if (ret == nr && desc->count) 1467 continue; 1468 break;
In this block, the page is present in the page cache and ready to be read by the file read actor function.
1470 /*
1471 * Ok, the page was not immediately readable, so let's try to read
* ahead while we're at it..
1472 */
1473 page_not_up_to_date:
1474 generic_file_readahead(reada_ok, filp, inode, page);
1475
1476 if (Page_Uptodate(page))
1477 goto page_ok;
1478
1479 /* Get exclusive access to the page ... */
1480 lock_page(page);
1481
1482 /* Did it get unhashed before we got the lock? */
1483 if (!page->mapping) {
1484 UnlockPage(page);
1485 page_cache_release(page);
1486 continue;
1487 }
1488
1489 /* Did somebody else fill it already? */
1490 if (Page_Uptodate(page)) {
1491 UnlockPage(page);
1492 goto page_ok;
1493 }
In this block, the page being read was not up-to-date with information on the disk. generic_file_readahead() is called to update the current page and readahead as IO is required anyway.
1495 readpage:
1496 /* ... and start the actual read. The read will
* unlock the page. */
1497 error = mapping->a_ops->readpage(filp, page);
1498
1499 if (!error) {
1500 if (Page_Uptodate(page))
1501 goto page_ok;
1502
1503 /* Again, try some read-ahead while waiting for
* the page to finish.. */
1504 generic_file_readahead(reada_ok, filp, inode, page);
1505 wait_on_page(page);
1506 if (Page_Uptodate(page))
1507 goto page_ok;
1508 error = -EIO;
1509 }
1510
1511 /* UHHUH! A synchronous read error occurred. Report it */
1512 desc->error = error;
1513 page_cache_release(page);
1514 break;
At this block, readahead failed to we synchronously read the page with the address_space supplied readpage() function.
1516 no_cached_page:
1517 /*
1518 * Ok, it wasn't cached, so we need to create a new
1519 * page..
1520 *
1521 * We get here with the page cache lock held.
1522 */
1523 if (!cached_page) {
1524 spin_unlock(&pagecache_lock);
1525 cached_page = page_cache_alloc(mapping);
1526 if (!cached_page) {
1527 desc->error = -ENOMEM;
1528 break;
1529 }
1530
1531 /*
1532 * Somebody may have added the page while we
1533 * dropped the page cache lock. Check for that.
1534 */
1535 spin_lock(&pagecache_lock);
1536 page = __find_page_nolock(mapping, index, *hash);
1537 if (page)
1538 goto found_page;
1539 }
1540
1541 /*
1542 * Ok, add the new page to the hash-queues...
1543 */
1544 page = cached_page;
1545 __add_to_page_cache(page, mapping, index, hash);
1546 spin_unlock(&pagecache_lock);
1547 lru_cache_add(page);
1548 cached_page = NULL;
1549
1550 goto readpage;
1551 }
In this block, the page does not exist in the page cache so allocate one and add it.
1552 1553 *ppos = ((loff_t) index << PAGE_CACHE_SHIFT) + offset; 1554 filp->f_reada = 1; 1555 if (cached_page) 1556 page_cache_release(cached_page); 1557 UPDATE_ATIME(inode); 1558 }
This function performs generic file read-ahead. Readahead is one of the few areas that is very heavily commented upon in the code. It is highly recommended that you read the comments in mm/filemap.c marked with “Read-ahead context”.
1222 static void generic_file_readahead(int reada_ok,
1223 struct file * filp, struct inode * inode,
1224 struct page * page)
1225 {
1226 unsigned long end_index;
1227 unsigned long index = page->index;
1228 unsigned long max_ahead, ahead;
1229 unsigned long raend;
1230 int max_readahead = get_max_readahead(inode);
1231
1232 end_index = inode->i_size >> PAGE_CACHE_SHIFT;
1233
1234 raend = filp->f_raend;
1235 max_ahead = 0;
1236
1237 /*
1238 * The current page is locked.
1239 * If the current position is inside the previous read IO request,
1240 * do not try to reread previously read ahead pages.
1241 * Otherwise decide or not to read ahead some pages synchronously.
1242 * If we are not going to read ahead, set the read ahead context
1243 * for this page only.
1244 */
1245 if (PageLocked(page)) {
1246 if (!filp->f_ralen ||
index >= raend ||
index + filp->f_rawin < raend) {
1247 raend = index;
1248 if (raend < end_index)
1249 max_ahead = filp->f_ramax;
1250 filp->f_rawin = 0;
1251 filp->f_ralen = 1;
1252 if (!max_ahead) {
1253 filp->f_raend = index + filp->f_ralen;
1254 filp->f_rawin += filp->f_ralen;
1255 }
1256 }
1257 }
This block has encountered a page that is locked so it must decide whether to temporarily disable readahead.
1258 /*
1259 * The current page is not locked.
1260 * If we were reading ahead and,
1261 * if the current max read ahead size is not zero and,
1262 * if the current position is inside the last read-ahead IO
1263 * request, it is the moment to try to read ahead asynchronously.
1264 * We will later force unplug device in order to force
* asynchronous read IO.
1265 */
1266 else if (reada_ok && filp->f_ramax && raend >= 1 &&
1267 index <= raend && index + filp->f_ralen >= raend) {
1268 /*
1269 * Add ONE page to max_ahead in order to try to have about the
1270 * same IO maxsize as synchronous read-ahead
* (MAX_READAHEAD + 1)*PAGE_CACHE_SIZE.
1271 * Compute the position of the last page we have tried to read
1272 * in order to begin to read ahead just at the next page.
1273 */
1274 raend -= 1;
1275 if (raend < end_index)
1276 max_ahead = filp->f_ramax + 1;
1277
1278 if (max_ahead) {
1279 filp->f_rawin = filp->f_ralen;
1280 filp->f_ralen = 0;
1281 reada_ok = 2;
1282 }
1283 }
This is one of the rare cases where the in-code commentary makes the code as clear as it possibly could be. Basically, it is saying that if the current page is not locked for IO, then extend the readahead window slight and remember that readahead is currently going well.
1284 /*
1285 * Try to read ahead pages.
1286 * We hope that ll_rw_blk() plug/unplug, coalescence, requests
1287 * sort and the scheduler, will work enough for us to avoid too
* bad actuals IO requests.
1288 */
1289 ahead = 0;
1290 while (ahead < max_ahead) {
1291 ahead ++;
1292 if ((raend + ahead) >= end_index)
1293 break;
1294 if (page_cache_read(filp, raend + ahead) < 0)
1295 break;
1296 }
This block performs the actual readahead by calling page_cache_read() for each of the pages in the readahead window. Note here how ahead is incremented for each page that is readahead.
1297 /*
1298 * If we tried to read ahead some pages,
1299 * If we tried to read ahead asynchronously,
1300 * Try to force unplug of the device in order to start an
1301 * asynchronous read IO request.
1302 * Update the read-ahead context.
1303 * Store the length of the current read-ahead window.
1304 * Double the current max read ahead size.
1305 * That heuristic avoid to do some large IO for files that are
1306 * not really accessed sequentially.
1307 */
1308 if (ahead) {
1309 filp->f_ralen += ahead;
1310 filp->f_rawin += filp->f_ralen;
1311 filp->f_raend = raend + ahead + 1;
1312
1313 filp->f_ramax += filp->f_ramax;
1314
1315 if (filp->f_ramax > max_readahead)
1316 filp->f_ramax = max_readahead;
1317
1318 #ifdef PROFILE_READAHEAD
1319 profile_readahead((reada_ok == 2), filp);
1320 #endif
1321 }
1322
1323 return;
1324 }
If readahead was successful, then update the readahead fields in the struct file to mark the progress. This is basically growing the readahead context but can be reset by do_generic_file_readahead() if it is found that the readahead is ineffective.
This is the generic mmap() function used by many struct files as their struct file_operations. It is mainly responsible for ensuring the appropriate address_space functions exist and setting what VMA operations to use.
2249 int generic_file_mmap(struct file * file,
struct vm_area_struct * vma)
2250 {
2251 struct address_space *mapping =
file->f_dentry->d_inode->i_mapping;
2252 struct inode *inode = mapping->host;
2253
2254 if ((vma->vm_flags & VM_SHARED) &&
(vma->vm_flags & VM_MAYWRITE)) {
2255 if (!mapping->a_ops->writepage)
2256 return -EINVAL;
2257 }
2258 if (!mapping->a_ops->readpage)
2259 return -ENOEXEC;
2260 UPDATE_ATIME(inode);
2261 vma->vm_ops = &generic_file_vm_ops;
2262 return 0;
2263 }
This section covers the path where a file is being truncated. The actual system call truncate() is implemented by sys_truncate() in fs/open.c. By the time the top-level function in the VM is called (vmtruncate()), the dentry information for the file has been updated and the inode's semaphore has been acquired.
This is the top-level VM function responsible for truncating a file. When it completes, all page table entries mapping pages that have been truncated have been unmapped and reclaimed if possible.
1042 int vmtruncate(struct inode * inode, loff_t offset)
1043 {
1044 unsigned long pgoff;
1045 struct address_space *mapping = inode->i_mapping;
1046 unsigned long limit;
1047
1048 if (inode->i_size < offset)
1049 goto do_expand;
1050 inode->i_size = offset;
1051 spin_lock(&mapping->i_shared_lock);
1052 if (!mapping->i_mmap && !mapping->i_mmap_shared)
1053 goto out_unlock;
1054
1055 pgoff = (offset + PAGE_CACHE_SIZE - 1) >> PAGE_CACHE_SHIFT;
1056 if (mapping->i_mmap != NULL)
1057 vmtruncate_list(mapping->i_mmap, pgoff);
1058 if (mapping->i_mmap_shared != NULL)
1059 vmtruncate_list(mapping->i_mmap_shared, pgoff);
1060
1061 out_unlock:
1062 spin_unlock(&mapping->i_shared_lock);
1063 truncate_inode_pages(mapping, offset);
1064 goto out_truncate;
1065
1066 do_expand:
1067 limit = current->rlim[RLIMIT_FSIZE].rlim_cur;
1068 if (limit != RLIM_INFINITY && offset > limit)
1069 goto out_sig;
1070 if (offset > inode->i_sb->s_maxbytes)
1071 goto out;
1072 inode->i_size = offset;
1073
1074 out_truncate:
1075 if (inode->i_op && inode->i_op->truncate) {
1076 lock_kernel();
1077 inode->i_op->truncate(inode);
1078 unlock_kernel();
1079 }
1080 return 0;
1081 out_sig:
1082 send_sig(SIGXFSZ, current, 0);
1083 out:
1084 return -EFBIG;
1085 }
This function cycles through all VMAs in an address_spaces list and calls zap_page_range() for the range of addresses which map a file that is being truncated.
1006 static void vmtruncate_list(struct vm_area_struct *mpnt,
unsigned long pgoff)
1007 {
1008 do {
1009 struct mm_struct *mm = mpnt->vm_mm;
1010 unsigned long start = mpnt->vm_start;
1011 unsigned long end = mpnt->vm_end;
1012 unsigned long len = end - start;
1013 unsigned long diff;
1014
1015 /* mapping wholly truncated? */
1016 if (mpnt->vm_pgoff >= pgoff) {
1017 zap_page_range(mm, start, len);
1018 continue;
1019 }
1020
1021 /* mapping wholly unaffected? */
1022 len = len >> PAGE_SHIFT;
1023 diff = pgoff - mpnt->vm_pgoff;
1024 if (diff >= len)
1025 continue;
1026
1027 /* Ok, partially affected.. */
1028 start += diff << PAGE_SHIFT;
1029 len = (len - diff) << PAGE_SHIFT;
1030 zap_page_range(mm, start, len);
1031 } while ((mpnt = mpnt->vm_next_share) != NULL);
1032 }
This function is the top-level pagetable-walk function which unmaps userpages in the specified range from a mm_struct.
360 void zap_page_range(struct mm_struct *mm,
unsigned long address, unsigned long size)
361 {
362 mmu_gather_t *tlb;
363 pgd_t * dir;
364 unsigned long start = address, end = address + size;
365 int freed = 0;
366
367 dir = pgd_offset(mm, address);
368
369 /*
370 * This is a long-lived spinlock. That's fine.
371 * There's no contention, because the page table
372 * lock only protects against kswapd anyway, and
373 * even if kswapd happened to be looking at this
374 * process we _want_ it to get stuck.
375 */
376 if (address >= end)
377 BUG();
378 spin_lock(&mm->page_table_lock);
379 flush_cache_range(mm, address, end);
380 tlb = tlb_gather_mmu(mm);
381
382 do {
383 freed += zap_pmd_range(tlb, dir, address, end - address);
384 address = (address + PGDIR_SIZE) & PGDIR_MASK;
385 dir++;
386 } while (address && (address < end));
387
388 /* this will flush any remaining tlb entries */
389 tlb_finish_mmu(tlb, start, end);
390
391 /*
392 * Update rss for the mm_struct (not necessarily current->mm)
393 * Notice that rss is an unsigned long.
394 */
395 if (mm->rss > freed)
396 mm->rss -= freed;
397 else
398 mm->rss = 0;
399 spin_unlock(&mm->page_table_lock);
400 }
This function is unremarkable. It steps through the PMDs that are affected by the requested range and calls zap_pte_range() for each one.
331 static inline int zap_pmd_range(mmu_gather_t *tlb, pgd_t * dir,
unsigned long address,
unsigned long size)
332 {
333 pmd_t * pmd;
334 unsigned long end;
335 int freed;
336
337 if (pgd_none(*dir))
338 return 0;
339 if (pgd_bad(*dir)) {
340 pgd_ERROR(*dir);
341 pgd_clear(dir);
342 return 0;
343 }
344 pmd = pmd_offset(dir, address);
345 end = address + size;
346 if (end > ((address + PGDIR_SIZE) & PGDIR_MASK))
347 end = ((address + PGDIR_SIZE) & PGDIR_MASK);
348 freed = 0;
349 do {
350 freed += zap_pte_range(tlb, pmd, address, end - address);
351 address = (address + PMD_SIZE) & PMD_MASK;
352 pmd++;
353 } while (address < end);
354 return freed;
355 }
This function calls tlb_remove_page() for each PTE in the requested pmd within the requested address range.
294 static inline int zap_pte_range(mmu_gather_t *tlb, pmd_t * pmd,
unsigned long address,
unsigned long size)
295 {
296 unsigned long offset;
297 pte_t * ptep;
298 int freed = 0;
299
300 if (pmd_none(*pmd))
301 return 0;
302 if (pmd_bad(*pmd)) {
303 pmd_ERROR(*pmd);
304 pmd_clear(pmd);
305 return 0;
306 }
307 ptep = pte_offset(pmd, address);
308 offset = address & ~PMD_MASK;
309 if (offset + size > PMD_SIZE)
310 size = PMD_SIZE - offset;
311 size &= PAGE_MASK;
312 for (offset=0; offset < size; ptep++, offset += PAGE_SIZE) {
313 pte_t pte = *ptep;
314 if (pte_none(pte))
315 continue;
316 if (pte_present(pte)) {
317 struct page *page = pte_page(pte);
318 if (VALID_PAGE(page) && !PageReserved(page))
319 freed ++;
320 /* This will eventually call __free_pte on the pte. */
321 tlb_remove_page(tlb, ptep, address + offset);
322 } else {
323 free_swap_and_cache(pte_to_swp_entry(pte));
324 pte_clear(ptep);
325 }
326 }
327
328 return freed;
329 }
This is the top-level function responsible for truncating all pages from the page cache that occur after lstart in a mapping.
327 void truncate_inode_pages(struct address_space * mapping,
loff_t lstart)
328 {
329 unsigned long start = (lstart + PAGE_CACHE_SIZE - 1) >>
PAGE_CACHE_SHIFT;
330 unsigned partial = lstart & (PAGE_CACHE_SIZE - 1);
331 int unlocked;
332
333 spin_lock(&pagecache_lock);
334 do {
335 unlocked = truncate_list_pages(&mapping->clean_pages,
start, &partial);
336 unlocked |= truncate_list_pages(&mapping->dirty_pages,
start, &partial);
337 unlocked |= truncate_list_pages(&mapping->locked_pages,
start, &partial);
338 } while (unlocked);
339 /* Traversed all three lists without dropping the lock */
340 spin_unlock(&pagecache_lock);
341 }
This function searches the requested list (head) which is part of an address_space. If pages are found after start, they will be truncated.
259 static int truncate_list_pages(struct list_head *head,
unsigned long start,
unsigned *partial)
260 {
261 struct list_head *curr;
262 struct page * page;
263 int unlocked = 0;
264
265 restart:
266 curr = head->prev;
267 while (curr != head) {
268 unsigned long offset;
269
270 page = list_entry(curr, struct page, list);
271 offset = page->index;
272
273 /* Is one of the pages to truncate? */
274 if ((offset >= start) ||
(*partial && (offset + 1) == start)) {
275 int failed;
276
277 page_cache_get(page);
278 failed = TryLockPage(page);
279
280 list_del(head);
281 if (!failed)
282 /* Restart after this page */
283 list_add_tail(head, curr);
284 else
285 /* Restart on this page */
286 list_add(head, curr);
287
288 spin_unlock(&pagecache_lock);
289 unlocked = 1;
290
291 if (!failed) {
292 if (*partial && (offset + 1) == start) {
293 truncate_partial_page(page, *partial);
294 *partial = 0;
295 } else
296 truncate_complete_page(page);
297
298 UnlockPage(page);
299 } else
300 wait_on_page(page);
301
302 page_cache_release(page);
303
304 if (current->need_resched) {
305 __set_current_state(TASK_RUNNING);
306 schedule();
307 }
308
309 spin_lock(&pagecache_lock);
310 goto restart;
311 }
312 curr = curr->prev;
313 }
314 return unlocked;
315 }
239 static void truncate_complete_page(struct page *page)
240 {
241 /* Leave it on the LRU if it gets converted into
* anonymous buffers */
242 if (!page->buffers || do_flushpage(page, 0))
243 lru_cache_del(page);
244
245 /*
246 * We remove the page from the page cache _after_ we have
247 * destroyed all buffer-cache references to it. Otherwise some
248 * other process might think this inode page is not in the
249 * page cache and creates a buffer-cache alias to it causing
250 * all sorts of fun problems ...
251 */
252 ClearPageDirty(page);
253 ClearPageUptodate(page);
254 remove_inode_page(page);
255 page_cache_release(page);
256 }
This function is responsible for flushing all buffers associated with a page.
223 static int do_flushpage(struct page *page, unsigned long offset)
224 {
225 int (*flushpage) (struct page *, unsigned long);
226 flushpage = page->mapping->a_ops->flushpage;
227 if (flushpage)
228 return (*flushpage)(page, offset);
229 return block_flushpage(page, offset);
230 }
This function partially truncates a page by zeroing out the higher bytes no longer in use and flushing any associated buffers.
232 static inline void truncate_partial_page(struct page *page,
unsigned partial)
233 {
234 memclear_highpage_flush(page, partial, PAGE_CACHE_SIZE-partial);
235 if (page->buffers)
236 do_flushpage(page, partial);
237 }
This is the generic nopage() function used by many VMAs. This loops around itself with a large number of goto's which can be difficult to trace but there is nothing novel here. It is principally responsible for fetching the faulting page from either the pgae cache or reading it from disk. If appropriate it will also perform file read-ahead.
1994 struct page * filemap_nopage(struct vm_area_struct * area,
unsigned long address,
int unused)
1995 {
1996 int error;
1997 struct file *file = area->vm_file;
1998 struct address_space *mapping =
file->f_dentry->d_inode->i_mapping;
1999 struct inode *inode = mapping->host;
2000 struct page *page, **hash;
2001 unsigned long size, pgoff, endoff;
2002
2003 pgoff = ((address - area->vm_start) >> PAGE_CACHE_SHIFT) +
area->vm_pgoff;
2004 endoff = ((area->vm_end - area->vm_start) >> PAGE_CACHE_SHIFT) +
area->vm_pgoff;
2005
This block acquires the struct file, addres_space and inode important for this page fault. It then acquires the starting offset within the file needed for this fault and the offset that corresponds to the end of this VMA. The offset is the end of the VMA instead of the end of the page in case file read-ahead is performed.
2006 retry_all:
2007 /*
2008 * An external ptracer can access pages that normally aren't
2009 * accessible..
2010 */
2011 size = (inode->i_size + PAGE_CACHE_SIZE - 1) >> PAGE_CACHE_SHIFT;
2012 if ((pgoff >= size) && (area->vm_mm == current->mm))
2013 return NULL;
2014
2015 /* The "size" of the file, as far as mmap is concerned, isn't
bigger than the mapping */
2016 if (size > endoff)
2017 size = endoff;
2018
2019 /*
2020 * Do we have something in the page cache already?
2021 */
2022 hash = page_hash(mapping, pgoff);
2023 retry_find:
2024 page = __find_get_page(mapping, pgoff, hash);
2025 if (!page)
2026 goto no_cached_page;
2027
2028 /*
2029 * Ok, found a page in the page cache, now we need to check
2030 * that it's up-to-date.
2031 */
2032 if (!Page_Uptodate(page))
2033 goto page_not_uptodate;
2035 success: 2036 /* 2037 * Try read-ahead for sequential areas. 2038 */ 2039 if (VM_SequentialReadHint(area)) 2040 nopage_sequential_readahead(area, pgoff, size); 2041 2042 /* 2043 * Found the page and have a reference on it, need to check sharing 2044 * and possibly copy it over to another page.. 2045 */ 2046 mark_page_accessed(page); 2047 flush_page_to_ram(page); 2048 return page; 2049
2050 no_cached_page: 2051 /* 2052 * If the requested offset is within our file, try to read 2053 * a whole cluster of pages at once. 2054 * 2055 * Otherwise, we're off the end of a privately mapped file, 2056 * so we need to map a zero page. 2057 */ 2058 if ((pgoff < size) && !VM_RandomReadHint(area)) 2059 error = read_cluster_nonblocking(file, pgoff, size); 2060 else 2061 error = page_cache_read(file, pgoff); 2062 2063 /* 2064 * The page we want has now been added to the page cache. 2065 * In the unlikely event that someone removed it in the 2066 * meantime, we'll just come back here and read it again. 2067 */ 2068 if (error >= 0) 2069 goto retry_find; 2070 2071 /* 2072 * An error return from page_cache_read can result if the 2073 * system is low on memory, or a problem occurs while trying 2074 * to schedule I/O. 2075 */ 2076 if (error == -ENOMEM) 2077 return NOPAGE_OOM; 2078 return NULL;
2080 page_not_uptodate:
2081 lock_page(page);
2082
2083 /* Did it get unhashed while we waited for it? */
2084 if (!page->mapping) {
2085 UnlockPage(page);
2086 page_cache_release(page);
2087 goto retry_all;
2088 }
2089
2090 /* Did somebody else get it up-to-date? */
2091 if (Page_Uptodate(page)) {
2092 UnlockPage(page);
2093 goto success;
2094 }
2095
2096 if (!mapping->a_ops->readpage(file, page)) {
2097 wait_on_page(page);
2098 if (Page_Uptodate(page))
2099 goto success;
2100 }
In this block, the page was found but it was not up-to-date so the reasons for the page not being up to date are checked. If it looks ok, the appropriate readpage() function is called to resync the page.
2101
2102 /*
2103 * Umm, take care of errors if the page isn't up-to-date.
2104 * Try to re-read it _once_. We do this synchronously,
2105 * because there really aren't any performance issues here
2106 * and we need to check for errors.
2107 */
2108 lock_page(page);
2109
2110 /* Somebody truncated the page on us? */
2111 if (!page->mapping) {
2112 UnlockPage(page);
2113 page_cache_release(page);
2114 goto retry_all;
2115 }
2116
2117 /* Somebody else successfully read it in? */
2118 if (Page_Uptodate(page)) {
2119 UnlockPage(page);
2120 goto success;
2121 }
2122 ClearPageError(page);
2123 if (!mapping->a_ops->readpage(file, page)) {
2124 wait_on_page(page);
2125 if (Page_Uptodate(page))
2126 goto success;
2127 }
2128
2129 /*
2130 * Things didn't work out. Return zero to tell the
2131 * mm layer so, possibly freeing the page cache page first.
2132 */
2133 page_cache_release(page);
2134 return NULL;
2135 }
In this path, the page is not up-to-date due to some IO error. A second attempt is made to read the page data and if it fails, return.
This function adds the page corresponding to the offset within the file to the page cache if it does not exist there already.
702 static int page_cache_read(struct file * file,
unsigned long offset)
703 {
704 struct address_space *mapping =
file->f_dentry->d_inode->i_mapping;
705 struct page **hash = page_hash(mapping, offset);
706 struct page *page;
707
708 spin_lock(&pagecache_lock);
709 page = __find_page_nolock(mapping, offset, *hash);
710 spin_unlock(&pagecache_lock);
711 if (page)
712 return 0;
713
714 page = page_cache_alloc(mapping);
715 if (!page)
716 return -ENOMEM;
717
718 if (!add_to_page_cache_unique(page, mapping, offset, hash)) {
719 int error = mapping->a_ops->readpage(file, page);
720 page_cache_release(page);
721 return error;
722 }
723 /*
724 * We arrive here in the unlikely event that someone
725 * raced with us and added our page to the cache first.
726 */
727 page_cache_release(page);
728 return 0;
729 }
This function is only called by filemap_nopage() when the VM_SEQ_READ flag has been specified in the VMA. When half of the current readahead-window has been faulted in, the next readahead window is scheduled for IO and pages from the previous window are freed.
1936 static void nopage_sequential_readahead(
struct vm_area_struct * vma,
1937 unsigned long pgoff, unsigned long filesize)
1938 {
1939 unsigned long ra_window;
1940
1941 ra_window = get_max_readahead(vma->vm_file->f_dentry->d_inode);
1942 ra_window = CLUSTER_OFFSET(ra_window + CLUSTER_PAGES - 1);
1943
1944 /* vm_raend is zero if we haven't read ahead
* in this area yet. */
1945 if (vma->vm_raend == 0)
1946 vma->vm_raend = vma->vm_pgoff + ra_window;
1947
1948 /*
1949 * If we've just faulted the page half-way through our window,
1950 * then schedule reads for the next window, and release the
1951 * pages in the previous window.
1952 */
1953 if ((pgoff + (ra_window >> 1)) == vma->vm_raend) {
1954 unsigned long start = vma->vm_pgoff + vma->vm_raend;
1955 unsigned long end = start + ra_window;
1956
1957 if (end > ((vma->vm_end >> PAGE_SHIFT) + vma->vm_pgoff))
1958 end = (vma->vm_end >> PAGE_SHIFT) + vma->vm_pgoff;
1959 if (start > end)
1960 return;
1961
1962 while ((start < end) && (start < filesize)) {
1963 if (read_cluster_nonblocking(vma->vm_file,
1964 start, filesize) < 0)
1965 break;
1966 start += CLUSTER_PAGES;
1967 }
1968 run_task_queue(&tq_disk);
1969
1970 /* if we're far enough past the beginning of this area,
1971 recycle pages that are in the previous window. */
1972 if (vma->vm_raend >
(vma->vm_pgoff + ra_window + ra_window)) {
1973 unsigned long window = ra_window << PAGE_SHIFT;
1974
1975 end = vma->vm_start + (vma->vm_raend << PAGE_SHIFT);
1976 end -= window + window;
1977 filemap_sync(vma, end - window, window, MS_INVALIDATE);
1978 }
1979
1980 vma->vm_raend += ra_window;
1981 }
1982
1983 return;
1984 }
737 static int read_cluster_nonblocking(struct file * file,
unsigned long offset,
738 unsigned long filesize)
739 {
740 unsigned long pages = CLUSTER_PAGES;
741
742 offset = CLUSTER_OFFSET(offset);
743 while ((pages-- > 0) && (offset < filesize)) {
744 int error = page_cache_read(file, offset);
745 if (error < 0)
746 return error;
747 offset ++;
748 }
749
750 return 0;
751 }
This function will fault in a number of pages after the current entry. It will stop with either CLUSTER_PAGES have been swapped in or an unused swap entry is found.
1093 void swapin_readahead(swp_entry_t entry)
1094 {
1095 int i, num;
1096 struct page *new_page;
1097 unsigned long offset;
1098
1099 /*
1100 * Get the number of handles we should do readahead io to.
1101 */
1102 num = valid_swaphandles(entry, &offset);
1103 for (i = 0; i < num; offset++, i++) {
1104 /* Ok, do the async read-ahead now */
1105 new_page = read_swap_cache_async(SWP_ENTRY(SWP_TYPE(entry),
offset));
1106 if (!new_page)
1107 break;
1108 page_cache_release(new_page);
1109 }
1110 return;
1111 }
This function determines how many pages should be readahead from swap starting from offset. It will readahead to the next unused swap slot but at most, it will return CLUSTER_PAGES.
1238 int valid_swaphandles(swp_entry_t entry, unsigned long *offset)
1239 {
1240 int ret = 0, i = 1 << page_cluster;
1241 unsigned long toff;
1242 struct swap_info_struct *swapdev = SWP_TYPE(entry) + swap_info;
1243
1244 if (!page_cluster) /* no readahead */
1245 return 0;
1246 toff = (SWP_OFFSET(entry) >> page_cluster) << page_cluster;
1247 if (!toff) /* first page is swap header */
1248 toff++, i--;
1249 *offset = toff;
1250
1251 swap_device_lock(swapdev);
1252 do {
1253 /* Don't read-ahead past the end of the swap area */
1254 if (toff >= swapdev->max)
1255 break;
1256 /* Don't read in free or bad pages */
1257 if (!swapdev->swap_map[toff])
1258 break;
1259 if (swapdev->swap_map[toff] == SWAP_MAP_BAD)
1260 break;
1261 toff++;
1262 ret++;
1263 } while (--i);
1264 swap_device_unlock(swapdev);
1265 return ret;
1266 }