The kernel may only directly address memory for which it has set up a page table entry. In the most common case, the user/kernel address space split of 3GiB/1GiB implies that at best only 896MiB of memory may be directly accessed at any given time on a 32-bit machine as explained in Section 4.1. On 64-bit hardware, this is not really an issue as there is more than enough virtual address space. It is highly unlikely there will be machines running 2.4 kernels with more than terabytes of RAM.
There are many high end 32-bit machines that have more than 1GiB of memory and the inconveniently located memory cannot be simply ignored. The solution Linux uses is to temporarily map pages from high memory into the lower page tables. This will be discussed in Section 9.2.
High memory and IO have a related problem which must be addressed, as not all devices are able to address high memory or all the memory available to the CPU. This may be the case if the CPU has PAE extensions enabled, the device is limited to addresses the size of a signed 32-bit integer (2GiB) or a 32-bit device is being used on a 64-bit architecture. Asking the device to write to memory will fail at best and possibly disrupt the kernel at worst. The solution to this problem is to use a bounce buffer and this will be discussed in Section 9.4.
This chapter begins with a brief description of how the Persistent Kernel Map (PKMap) address space is managed before talking about how pages are mapped and unmapped from high memory. The subsequent section will deal with the case where the mapping must be atomic before discussing bounce buffers in depth. Finally we will talk about how emergency pools are used for when memory is very tight.
Space is reserved at the top of the kernel page tables from PKMAP_BASE to FIXADDR_START for a PKMap. The size of the space reserved varies slightly. On the x86, PKMAP_BASE is at 0xFE000000 and the address of FIXADDR_START is a compile time constant that varies with configure options but is typically only a few pages located near the end of the linear address space. This means that there is slightly below 32MiB of page table space for mapping pages from high memory into usable space.
For mapping pages, a single page set of PTEs is stored at the beginning of the PKMap area to allow 1024 high pages to be mapped into low memory for short periods with the function kmap() and unmapped with kunmap(). The pool seems very small but the page is only mapped by kmap() for a very short time. Comments in the code indicate that there was a plan to allocate contiguous page table entries to expand this area but it has remained just that, comments in the code, so a large portion of the PKMap is unused.
The page table entry for use with kmap() is called pkmap_page_table which is located at PKMAP_BASE and set up during system initialisation. On the x86, this takes place at the end of the pagetable_init() function. The pages for the PGD and PMD entries are allocated by the boot memory allocator to ensure they exist.
The current state of the page table entries is managed by a simple array called called pkmap_count which has LAST_PKMAP entries in it. On an x86 system without PAE, this is 1024 and with PAE, it is 512. More accurately, albeit not expressed in code, the LAST_PKMAP variable is equivalent to PTRS_PER_PTE.
Each element is not exactly a reference count but it is very close. If the entry is 0, the page is free and has not been used since the last TLB flush. If it is 1, the slot is unused but a page is still mapped there waiting for a TLB flush. Flushes are delayed until every slot has been used at least once as a global flush is required for all CPUs when the global page tables are modified and is extremely expensive. Any higher value is a reference count of n-1 users of the page.
The API for mapping pages from high memory is described in Table 9.1. The main function for mapping a page is kmap(). For users that do not wish to block, kmap_nonblock() is available and interrupt users have kmap_atomic(). The kmap pool is quite small so it is important that users of kmap() call kunmap() as quickly as possible because the pressure on this small window grows incrementally worse as the size of high memory grows in comparison to low memory.
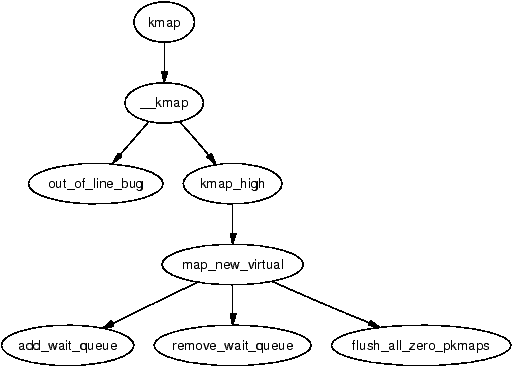
Figure 9.1: Call Graph: kmap()
The kmap() function itself is fairly simple. It first checks to make sure an interrupt is not calling this function(as it may sleep) and calls out_of_line_bug() if true. An interrupt handler calling BUG() would panic the system so out_of_line_bug() prints out bug information and exits cleanly. The second check is that the page is below highmem_start_page as pages below this mark are already visible and do not need to be mapped.
It then checks if the page is already in low memory and simply returns the address if it is. This way, users that need kmap() may use it unconditionally knowing that if it is already a low memory page, the function is still safe. If it is a high page to be mapped, kmap_high() is called to begin the real work.
The kmap_high() function begins with checking the page→virtual field which is set if the page is already mapped. If it is NULL, map_new_virtual() provides a mapping for the page.
Creating a new virtual mapping with map_new_virtual() is a simple case of linearly scanning pkmap_count. The scan starts at last_pkmap_nr instead of 0 to prevent searching over the same areas repeatedly between kmap()s. When last_pkmap_nr wraps around to 0, flush_all_zero_pkmaps() is called to set all entries from 1 to 0 before flushing the TLB.
If, after another scan, an entry is still not found, the process sleeps on the pkmap_map_wait wait queue until it is woken up after the next kunmap().
Once a mapping has been created, the corresponding entry in the pkmap_count array is incremented and the virtual address in low memory returned.
void * kmap(struct page *page) ĀTakes a struct page from high memory and maps it into low memory. The address returned is the virtual address of the mapping void * kmap_nonblock(struct page *page) ĀThis is the same as kmap() except it will not block if no slots are available and will instead return NULL. This is not the same as kmap_atomic() which uses specially reserved slots void * kmap_atomic(struct page *page, enum km_type type) ĀThere are slots maintained in the map for atomic use by interrupts (see Section 9.3). Their use is heavily discouraged and callers of this function may not sleep or schedule. This function will map a page from high memory atomically for a specific purpose
Table 9.1: High Memory Mapping API
The API for unmapping pages from high memory is described in Table 9.2. The kunmap() function, like its complement, performs two checks. The first is an identical check to kmap() for usage from interrupt context. The second is that the page is below highmem_start_page. If it is, the page already exists in low memory and needs no further handling. Once established that it is a page to be unmapped, kunmap_high() is called to perform the unmapping.
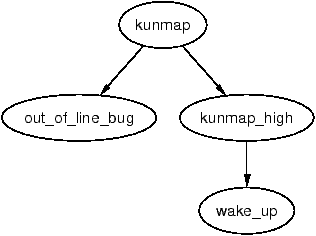
Figure 9.2: Call Graph: kunmap()
The kunmap_high() is simple in principle. It decrements the corresponding element for this page in pkmap_count. If it reaches 1 (remember this means no more users but a TLB flush is required), any process waiting on the pkmap_map_wait is woken up as a slot is now available. The page is not unmapped from the page tables then as that would require a TLB flush. It is delayed until flush_all_zero_pkmaps() is called.
Table 9.2: High Memory Unmapping API
The use of kmap_atomic() is discouraged but slots are reserved for each CPU for when they are necessary, such as when bounce buffers, are used by devices from interrupt. There are a varying number of different requirements an architecture has for atomic high memory mapping which are enumerated by km_type. The total number of uses is KM_TYPE_NR. On the x86, there are a total of six different uses for atomic kmaps.
There are KM_TYPE_NR entries per processor are reserved at boot time for atomic mapping at the location FIX_KMAP_BEGIN and ending at FIX_KMAP_END. Obviously a user of an atomic kmap may not sleep or exit before calling kunmap_atomic() as the next process on the processor may try to use the same entry and fail.
The function kmap_atomic() has the very simple task of mapping the requested page to the slot set aside in the page tables for the requested type of operation and processor. The function kunmap_atomic() is interesting as it will only clear the PTE with pte_clear() if debugging is enabled. It is considered unnecessary to bother unmapping atomic pages as the next call to kmap_atomic() will simply replace it making TLB flushes unnecessary.
Bounce buffers are required for devices that cannot access the full range of memory available to the CPU. An obvious example of this is when a device does not address with as many bits as the CPU, such as 32-bit devices on 64-bit architectures or recent Intel processors with PAE enabled.
The basic concept is very simple. A bounce buffer resides in memory low enough for a device to copy from and write data to. It is then copied to the desired user page in high memory. This additional copy is undesirable, but unavoidable. Pages are allocated in low memory which are used as buffer pages for DMA to and from the device. This is then copied by the kernel to the buffer page in high memory when IO completes so the bounce buffer acts as a type of bridge. There is significant overhead to this operation as at the very least it involves copying a full page but it is insignificant in comparison to swapping out pages in low memory.
Blocks, typically around 1KiB are packed into pages and managed by a struct buffer_head allocated by the slab allocator. Users of buffer heads have the option of registering a callback function. This function is stored in buffer_head→b_end_io() and called when IO completes. It is this mechanism that bounce buffers uses to have data copied out of the bounce buffers. The callback registered is the function bounce_end_io_write().
Any other feature of buffer heads or how they are used by the block layer is beyond the scope of this document and more the concern of the IO layer.
The creation of a bounce buffer is a simple affair which is started by the create_bounce() function. The principle is very simple, create a new buffer using a provided buffer head as a template. The function takes two parameters which are a read/write parameter (rw) and the template buffer head to use (bh_orig).
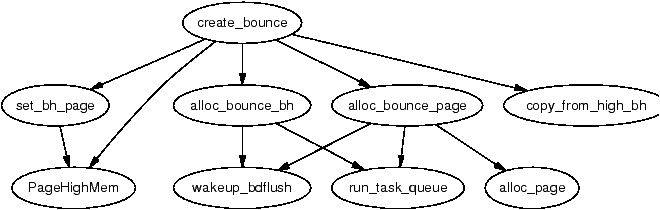
Figure 9.3: Call Graph: create_bounce()
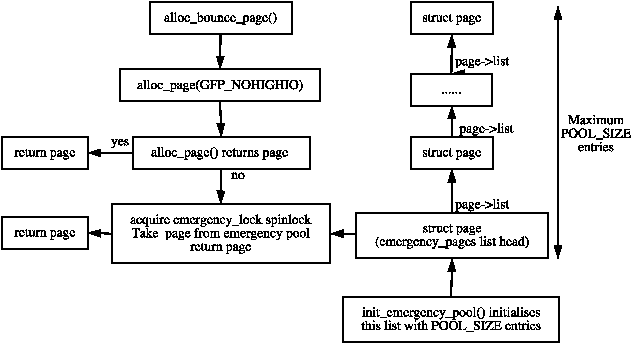
A page is allocated for the buffer itself with the function alloc_bounce_page() which is a wrapper around alloc_page() with one important addition. If the allocation is unsuccessful, there is an emergency pool of pages and buffer heads available for bounce buffers. This is discussed further in Section 9.5.
The buffer head is, predictably enough, allocated with alloc_bounce_bh() which, similar in principle to alloc_bounce_page(), calls the slab allocator for a buffer_head and uses the emergency pool if one cannot be allocated. Additionally, bdflush is woken up to start flushing dirty buffers out to disk so that buffers are more likely to be freed soon.
Once the page and buffer_head have been allocated, information is copied from the template buffer_head into the new one. Since part of this operation may use kmap_atomic(), bounce buffers are only created with the IRQ safe io_request_lock held. The IO completion callbacks are changed to be either bounce_end_io_write() or bounce_end_io_read() depending on whether this is a read or write buffer so the data will be copied to and from high memory.
The most important aspect of the allocations to note is that the GFP flags specify that no IO operations involving high memory may be used. This is specified with SLAB_NOHIGHIO to the slab allocator and GFP_NOHIGHIO to the buddy allocator. This is important as bounce buffers are used for IO operations with high memory. If the allocator tries to perform high memory IO, it will recurse and eventually crash.
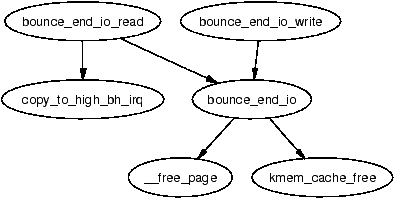
Figure 9.4: Call Graph: bounce_end_io_read/write()
Data is copied via the bounce buffer differently depending on whether it is a read or write buffer. If the buffer is for writes to the device, the buffer is populated with the data from high memory during bounce buffer creation with the function copy_from_high_bh(). The callback function bounce_end_io_write() will complete the IO later when the device is ready for the data.
If the buffer is for reading from the device, no data transfer may take place until the device is ready. When it is, the interrupt handler for the device calls the callback function bounce_end_io_read() which copies the data to high memory with copy_to_high_bh_irq().
In either case the buffer head and page may be reclaimed by bounce_end_io() once the IO has completed and the IO completion function for the template buffer_head() is called. If the emergency pools are not full, the resources are added to the pools otherwise they are freed back to the respective allocators.
Two emergency pools of buffer_heads and pages are maintained for the express use by bounce buffers. If memory is too tight for allocations, failing to complete IO requests is going to compound the situation as buffers from high memory cannot be freed until low memory is available. This leads to processes halting, thus preventing the possibility of them freeing up their own memory.
The pools are initialised by init_emergency_pool() to contain POOL_SIZE entries each which is currently defined as 32. The pages are linked via the page→list field on a list headed by emergency_pages. Figure 9.5 illustrates how pages are stored on emergency pools and acquired when necessary.
The buffer_heads are very similar as they linked via the buffer_head→inode_buffers on a list headed by emergency_bhs. The number of entries left on the pages and buffer lists are recorded by two counters nr_emergency_pages and nr_emergency_bhs respectively and the two lists are protected by the emergency_lock spinlock.
Figure 9.5: Acquiring Pages from Emergency Pools
In 2.4, the high memory manager was the only subsystem that maintained emergency pools of pages. In 2.6, memory pools are implemented as a generic concept when a minimum amount of “stuff” needs to be reserved for when memory is tight. “Stuff” in this case can be any type of object such as pages in the case of the high memory manager or, more frequently, some object managed by the slab allocator. Pools are initialised with mempool_create() which takes a number of arguments. They are the minimum number of objects that should be reserved (min_nr), an allocator function for the object type (alloc_fn()), a free function (free_fn()) and optional private data that is passed to the allocate and free functions.
The memory pool API provides two generic allocate and free functions called mempool_alloc_slab() and mempool_free_slab(). When the generic functions are used, the private data is the slab cache that objects are to be allocated and freed from.
In the case of the high memory manager, two pools of pages are created. On page pool is for normal use and the second page pool is for use with ISA devices that must allocate from ZONE_DMA. The allocate function is page_pool_alloc() and the private data parameter passed indicates the GFP flags to use. The free function is page_pool_free(). The memory pools replace the emergency pool code that exists in 2.4.
To allocate or free objects from the memory pool, the memory pool API functions mempool_alloc() and mempool_free() are provided. Memory pools are destroyed with mempool_destroy().
In 2.4, the field page→virtual was used to store the address of the page within the pkmap_count array. Due to the number of struct pages that exist in a high memory system, this is a very large penalty to pay for the relatively small number of pages that need to be mapped into ZONE_NORMAL. 2.6 still has this pkmap_count array but it is managed very differently.
In 2.6, a hash table called page_address_htable is created. This table is hashed based on the address of the struct page and the list is used to locate struct page_address_slot. This struct has two fields of interest, a struct page and a virtual address. When the kernel needs to find the virtual address used by a mapped page, it is located by traversing through this hash bucket. How the page is actually mapped into lower memory is essentially the same as 2.4 except now page→virtual is no longer required.
The last major change is that the struct bio is now used instead of the struct buffer_head when performing IO. How bio structures work is beyond the scope of this book. However, the principle reason that bio structures were introduced is so that IO could be performed in blocks of whatever size the underlying device supports. In 2.4, all IO had to be broken up into page sized chunks regardless of the transfer rate of the underlying device.